先前业界在目标检测主要集中在封闭场景中,并且取得了较高的准确率,但在开放场景中的表现却不尽如人意。具有挑战性的开放世界问题之一是自动驾驶对极端情况的检测。现有的检测器在处理这些情况时遇到了困难,严重依赖视觉外观并且泛化能力较差。在本文中,介绍了一种解决方案,通过减少已知类和未知类之间的差异,并引入多模态增强的对象概念学习器。利用以视觉为中心和图像文本模式,我们的半监督学习框架向学生模型传授对象性知识,从而实现类感知检测。本文提到的方法,用于角点案例检测的多模态增强对象学习器(MENOL),可以以较低的训练成本显着提高新类的召回率。
自动驾驶场景目标检测方法概述
自动驾驶技术追求的目标是在无需人工干预的情况下驾驶车辆,同时保证安全。物体检测是自动驾驶的一项基本任务,旨在识别和定位图像中的物体。深度学习的采用加速了目标检测研究的进展,人们提出了许多精心设计的深度神经网络来提高目标检测的准确性。现有的目标检测方法已经在封闭场景中实现了高精度,其中目标类别是预先定义的。然而,这些方法在开放世界场景中的性能并不令人满意,因为在开放世界场景中可能会遇到新的对象类别和实例。

图 1:极端情况的示例
自动驾驶中的一个主要开放世界对象检测挑战称为极端情况检测。极端情况由两种类型组成:(i)新颖类的实例(例如,失控的轮胎)和(ii)普通类的新颖实例(例如,翻倒的卡车)。极端情况的示例如图 1 所示,大多数自动驾驶数据集中通常不存在“交通锥”类别。然而,大多数检测器通常无法检测训练过程中未见过或很少见过的新物体,导致召回率低、漏报率高。
自动驾驶中的物体检测可能会遇到极端情况问题,处理这个问题的一种方法称为开放世界对象检测(OWOD)的工作提出了这种范式,旨在检测一组给定的已知对象,同时学习识别未知对象。ORE是第一个开放世界的物体检测器,它利用可学习的基于能量的未知标识符来区分未知类别和已知类别。OW-DETR通过使用基于Transformer的框架来扩展 ORE,以明确地解决端到端的 OWOD 挑战。OWOD 的工作有希望改进出相对于闭集目标检测器,但它们仍然存在许多局限性。具体来说,这些完全监督的方法对已知类别有强烈的偏见,导致他们无法检测到新的极端情况类别。此外,如果训练数据集不够大,它们的泛化性能也会很差。
最近,许多基于多种模式的研究取得了重大进展。
计算机视觉中的闭集对象检测涉及识别和定位图像中的预定义对象。方法可分为一级或两级。像 YOLO这样的单阶段方法直接在单个网络中执行定位和分类。以 Faster R-CNN为例,其包含两阶段方法:具有用于候选框生成的提取阶段和用于框分类和细化的后续阶段。虽然两阶段模型提供了更高的精度,但由于额外的提案生成阶段,它们会产生更大的计算成本。
开放世界对象检测涉及预测对象的类别标签和边界框,包括模型必须学习的未知类别对象。约瑟夫等人提出的ORE是第一个使用区域提议网络(RPN)来生成与类无关的开放世界对象检测器。它对伪未知物进行自动标记来进行训练,使用可学习的基于能量的标识符来区分未知类别。古普塔等人提出了一种基于端到端Transformer的框架,通过注意力驱动的伪标签、新颖性分类和对象性评分来解决开放世界的对象检测挑战。黄等识别基于 RGB 的检测器中的过度拟合问题,并引入 GOOD,这是一种利用几何线索来增强检测性能的新颖框架。
多样化的信息有助于多种模式的成功,它为模型提供了理解世界的各种视角。视觉语言模型 (VLM) 和开放词汇对象检测涉及通过集成多种模式来检测未学习类别的对象,VLM 是对齐图像和文本表示的大型预训练模型。CLIP 的提议表明图像-文本对包含比预定义概念更边界的视觉概念。视觉表示可以通过大量的图像-文本对来学习。大规模视觉语言模型CLIP 的引入促进了开放词汇目标检测(OVOD)和零样本目标检测(ZSOD)的发展。他们都专注于如何在基类上训练对象检测器,然后在推理过程中推广到新的类。对比语言-图像预训练(CLIP)在图像分类中表现出显着的零样本能力。
在 CLIP 成功的基础上,研究人员探索开放词汇对象检测 (OVOD),应用 VLM 来检测未见过类别的对象。OVOD的第一个工作是基于字幕信息提取,将单独的视觉嵌入与文本嵌入对齐,从而实现它们之间的强相关性。例如,Li等人介绍Grounded Language-Image Pre-training (GLIP),它是在区域词级别预训练的大规模视觉语言模型。大多数现有的ZSOD方法从基类中学习,并通过利用基类和新类别之间的相关性生成新类。尽管 OVOD 和 ZSOD 对于某些开放世界场景有效,但我们认为它们不适合解决极端情况问题。原因是类别的语义边界不够清晰,极端情况类别之间的差异较大。例如,“碎片”和“杂项”的类别不如“汽车”或“行人”的类别清晰,使得 OVOD 或 ZSOD 管道的视觉和语言表示空间很难对齐。
与 ZSOD 或 OVOD 相比,本文介绍了一种用于角点情况检测的多模态增强对象学习器(MENOL)。MENOL 主要侧重于学习客观性的概念并提高对新识别场景课程的回忆。许多研究将极端情况检测问题视为分布外 (OOD) 或异常检测问题。他们设计了非常复杂的规则来检测极端情况下的目标。然而,t-SNE 可视化(如下图 3)显示表示对于一些位置目标,其检测结果非常分散,因此很难设计这样的通用规则。
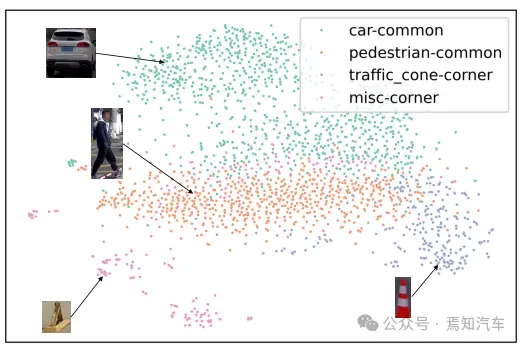
我们建议通过使用深度和法线的几何线索来缩小已知类和未知类之间的差距。为了学习对象性的概念,我们设计了一个多模态增强的对象性概念学习器,这是一种以视觉为中心的图像文本多模态设计。我们的 MENOL 被设计为半监督框架,使用客观概念学习器作为教师模型,为未标记数据(提取的深度和正常图像)生成与类别无关的伪框。然后将伪标记的深度和法线图像与完全注释的原始 RGB 图像合并,并输入学生模型以训练最终的类感知开放世界对象检测器。总的来说,我们提出的 MENOL 成功解决了上述问题,并以相对较低的训练成本显着提高了新类别的召回率。学习对象性概念并减少已知类和未知类之间的差异的想法是处理极端情况检测问题的通用方法。
本文方法论
我们的MENOL方法通过利用多种模式和半监督学习框架,提供了一种新颖的Pipeline来检测自动驾驶中的极端情况。为了减少已知类和未知类之间的差异,我们利用深度信息和法线信息这些几何线索为模型学习提供额外的知识和多样化的信息,这是一种以视觉为中心的多模态。
为了学习客观性概念并提高对新类别的回忆,我们训练客观性概念学习器对所有对象执行与类别无关的检测。为了将客观性概念的知识注入学习模型中,我们设计了一个半监督学习框架。客观概念学习器充当教师模型,为未标记的数据(提取的深度和正常图像)生成伪框。然后,将这些伪标记的深度和法线图像与完全注释的原始 RGB 图像合并来训练学生模型,这是用于极端情况检测任务的最终类感知开放世界对象检测器。
本文算法模型的概述如下图 2 所示。它由 4 个阶段组成。
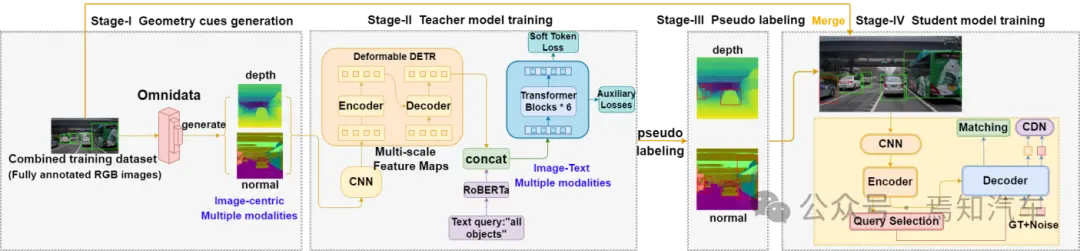
图2:MENOL框架概述
第一阶段:训练数据集中的 RGB 图像首先由现成的Omnidata模型进行预处理,以提取几何线索。这些几何线索信息主要包含图像深度信息和图像为中心的多模态信息。
第二阶段:生成的几何线索图像用于训练客观性概念学习器。该训练过程包括利用CNN网络对前置图像深度信息和几何信息进行有效处理生成多尺度图像特征信息。
第三阶段:训练好的客观概念学习器用作教师模型,为来自另一个自动驾驶数据集的深度和法线图像生成伪框。
第四阶段:伪标记深度和法线图像与完全注释的原始 RGB 图像合并,然后输入基于 DINO 的学生模型来训练最终的开放世界类感知对象检测器。过程中,仅需要对使用学生模型进行推理。
1、几何线索提取
深度关注物体的相对空间差异,忽略物体表面的细节,而法线则关注方向差异。减少已知和未知对象在几何线索方面的差异有利于模型学习对象性的概念。深度图像和法线图像以及原始 RGB 图像构成了以视觉为中心的多种模态,防止模型过度拟合训练类并在检测对象时仅依赖视觉外观线索。
如图2第一阶段所示,我们使用Omnidata模型从训练数据集中的原始RGB图像中提取深度和法线图像。Omnidata 模型在 Omnidata Starter Dataset (OSD) 上进行训练,使用跨任务一致性和 2D/3D 数据增强。它可以生成高质量的深度和法线图像,并且这些几何线索背后的不变性非常强大。
2、学习对象性的概念
受到 GOOD之前工作的启发,我们还使用几何线索来增强开放世界对象检测器的性能。GOOD 训练基于 OLN 的提案网络,使用已知类别的 RGB 图像来生成深度和法线图像的提案。然而,GOOD 有其局限性。首先,OLN 只是简单地用定位质量估计器替换 Faster R-CNN 的分类器头,并使用相对较小规模的图像来训练它。因此,该模型仍然对已知类有强烈的偏见,并且无法学习对象性的概念。如果训练数据集不够大,它在极端情况检测任务上表现不佳。另外,GOOD的提议网络是在RGB图像上训练的,需要生成深度图像和普通图像的Proposals,这两种图像的不同特征限制了潜在网络的泛化性能。最后,GOOD只能进行类别无关的目标检测,这与自动驾驶的实际应用不符。
下面介绍我们的方法是如何解决了这些限制的。
为了解决 GOOD 提议网络中已知类的过度拟合问题,我们提出使用对象概念学习器来对所有对象执行与类无关的检测。我们的客观性概念学习器是一种视觉语言多模式设计。使用可变形DETR架构作为视觉分支来提取视觉特征,并使用RoBERTa作为语言分支来对文本进行编码。
由于图像中的物体并不总是处于相同的比例,因此比例变化对于自动驾驶物体检测器来说是一个巨大的挑战。在我们的客观概念学习器中,图像首先被输入 CNN 主干以提取多尺度视觉特征。如图2阶段II所示,提取的特征随后被输入到Deformable DETR中以获得视觉表示向量。多尺度可变形注意力模块在多个尺度上计算注意力,以合并更好的上下文信息。为了降低计算成本,可变形注意力对参考(查询)图像位置周围的一小组键进行采样,以实现相对于图像特征图大小的线性复杂度。预训练的 RoBERTa 对文本查询输入进行编码并生成相应的隐藏向量序列。连接扁平图像特征和文本嵌入可能会破坏图像的空间结构。因此,更好的选择是使用后期多模态融合机制来融合图像特征和文本嵌入。
具体来说,首先使用 Deformable DETR 架构处理图像特征以获得对象查询表示。与文本嵌入连接后,它们被输入到 Transformer 架构中以融合多模态信息。在每个Transformer自注意力块之后应用输出头,并计算Soft Token损失和辅助损失以优化参数。软令牌丢失旨在从引用每个匹配对象的原始文本中预测Token的范围,而不是预测每个检测到的对象类别。该模型经过训练,可以预测所有标记位置上的均匀分布,这些标记位置对应于使用双向匹配与地面实况框匹配的每个预测框的对象。使用图像-文本多模态使模型能够从大量图像-文本对中学习并更好地理解对象性。
3、通过半监督学习框架注入对象性概念知识
先前的半监督目标检测(SSOD)工作取得了巨大成功,通常采用教师模型的伪标记。最近的研究将 SSOD 扩展到开放世界的物体检测,优于完全监督的方法。
由于对象概念学习器仅关注“什么是对象?”,因此它缺乏类感知检测能力。为了利用这些知识进行类感知检测,我们引入了半监督学习框架。如图2第三阶段和第四阶段所示,教师模型为未标记数据(提取的深度和正常图像)生成与类别无关的伪框,将客观概念知识注入学生模型中。考虑到这些图像中反映的不同方面,教师模型生成不同的伪框。该设计利用以视觉为中心的多种模式为学生模型提供多样化的信息。伪标记深度和法线图像与完全注释的 RGB 图像合并,并用于训练学生模型以进行开放世界的类感知对象检测。
学生模型采用基于 DINO的端到端架构,并具有 Swin Transformer 主干。它采用对比去噪训练、用于锚点初始化的混合查询选择以及用于框预测的前瞻两次方案。
4、目标优化
我们的学生模型的优化目标包括分类损失和框回归损失。分类损失是一般的Focal Loss,框回归损失计算为广义交并集 (GIoU) 损失和 L1 损失的组合。
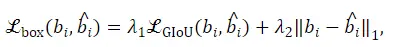
实验结果研究
我们使用 Omnidata 模型从 CODA 和 SODA10M 训练集的原始 RGB 图像中提取几何线索(深度和法线)。它们没有标签,但我们可以使用它们对应的 RGB 图像的注释作为它们的标签。然后,使用BLIP为来自CODA训练数据集的图像生成标题。深度图像和正常图像与原始 RGB 图像共享相同的标题。
对象性概念学习器的 CNN 主干使用在 ImageNet-1K 上预训练的 ResNet-101 的权重进行初始化。对象性概念学习器使用来自 MS COCO、Flickr30k 和 Visual Genome (VG) 的大约 1.3M 个对齐的图像-文本对进行预训练。这些数据集包含来自不同场景的各种对象。经过预训练,该模型在一定程度上学习了对象性的概念。提取的深度和正常图像以及 CODA 数据集中的 RGB 图像的组合,连同它们相应的标题一起被输入到对象性概念学习器中以对模型进行微调。在微调阶段,CNN 主干、可变形 DETR 和语言主干的参数被冻结,而后期融合 Transformer 的参数被更新。由于我们不关心物体的具体类别,而只关注“什么是物体?”,因此我们使用“所有物体”作为文本查询,在推理阶段生成与类别无关的预测。
经过训练的物体概念学习器充当教师模型,为我们训练数据集(即 SODA10M)中提取的深度和正常图像生成伪框。伪标记的深度和正常图像与完全注释的原始 RGB 图像合并并输入到学生模型中。学生模型是基于 DINO [17] 的闭集物体检测器。它在 Objects365 数据集(约 1.7M 张带注释的图像)上进行了预训练,并使用 Swin Transformer 大型主干。损失函数 1 的超参数设置为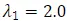 ,
,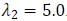 。我们使用 AdamW 优化器,初始学习率为 0.0001,权重衰减为 0.0001,来训练基于 DINO 的学生模型。训练过程使用 2 个 NVIDIA Geforce RTX 3090 GPU 和批处理大小为 2,在 35 个时期内完成,实现是基于 MMDetection 工具。
。我们使用 AdamW 优化器,初始学习率为 0.0001,权重衰减为 0.0001,来训练基于 DINO 的学生模型。训练过程使用 2 个 NVIDIA Geforce RTX 3090 GPU 和批处理大小为 2,在 35 个时期内完成,实现是基于 MMDetection 工具。
我们的 MENOL 和基线方法在 CODA-val 数据集上的表现如下表所示。我们的 MENOL 实现了 0.766 mAR-corner、0.798 mAR-agnostic、0.742 mAP-agnostic 和 0.711 mAP-common,大大优于基线模型。这表明我们的 MENOL 具有更好的极端情况检测能力。

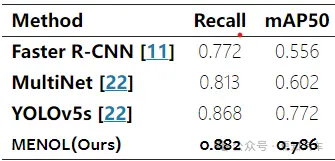
我们的 MENOL 和基线方法在 BDD100K-val 数据集上的表现如下表所示。我们的 MENOL 实现了0.882召回率和 0.786 mAP50,优于基线模型。这表明我们的 MENOL 仍然具有更好的常见物体检测能力。
我们的 MENOL 在 CODA 数据集上的检测结果如图 4 所示。从图中可以看出,基本上我们提出的算法对视觉感知场景中的所有目标都能完全的检测和识别。

总结
本文介绍了一种新颖的多模态增强对象概念学习器和一种基于半监督的开放世界对象检测器,用于自动驾驶中的极端情况检测,称为MENOL,它可以以相对较低的训练成本有效提高新类的召回率。MENOL 利用以视觉为中心和图像文本多模态学习,结合几何线索来解决自动驾驶中的极端情况检测挑战。通过有效地减少已知和未知类别之间的差异,MENOL 在新类别的召回方面表现出显著的改进,有助于提高不同场景中物体检测的稳健性。未来的工作可以探索利用更丰富的模态和更通用的物体概念学习模型,来提高自动驾驶中道路检测的性能。
来源:焉知汽车













