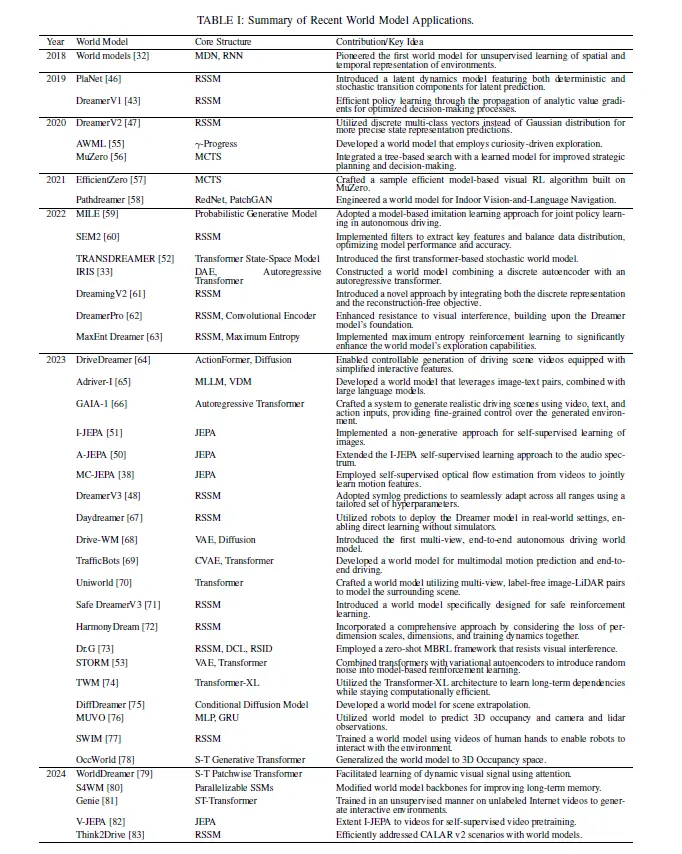
这一章节介绍了世界模型(world models)在不同领域的应用和研究进展。世界模型是一种能够对环境进行建模并预测未来状态的计算框架,具有广泛的应用前景。文章列举了多个领域中的世界模型应用案例,并详细介绍了其原理和技术细节。此外,还探讨了世界模型在未来的发展方向和可能面临的挑战。
世界模型通过自监督学习的方式从大量未标注的数据中提取出有价值的信息,从而增强模型的性能和效率。在驾驶场景生成方面,世界模型可以创造多样化、真实化的驾驶环境,丰富训练数据集,提高自动驾驶系统的鲁棒性和适应性。同时,在规划和控制策略方面,世界模型也可以帮助车辆进行未来预测和决策制定,提升行驶安全性和稳定性。随着研究的不断深入,世界模型逐渐向多模态方向发展,并与其他模型相结合,进一步拓展了其应用场景和效果。
(1)感知模块
这一基础组件充当系统的感官输入,类似于人类的感觉器官。采用先进的传感器和编码模块,例如变分自动编码器 (VAE) 、遮罩自动编码器 (MAE)和离散自动编码器 (DAE) 来处理和压缩环境输入(如图像、视频、文本、控制指令)到一个更易于管理的格式。该模块的有效性对于准确感知复杂多变的环境至关重要,它能够促进对环境的详细理解,进而指导模型做出后续预测和决策。
(2)记忆模块
扮演着类似人类海马体的角色,记忆模块对于记录和管理过去、现在及预测的世界状态及其相关成本或奖励至关重要 。它通过重播经历来实现短期和长期记忆功能,这一过程通过将过去的洞察融入未来的决策中来增强学习和适应能力。该模块合成和保留关键信息的能力对于随时间发展对环境动态的细致理解至关重要。
(3)控制/动作模块
这个模块直接负责通过动作与环境进行交互。评估当前状态和世界模型提供的预测,以确定实现特定目标(如最小化成本或最大化奖励)的最佳动作序列。该模块的精妙之处在于它能够整合感官数据、记忆和预测洞察,从而做出明智的战略决策,以应对真实世界情景的复杂性。此模块将决策过程与复杂的世界模型模块区分开来,并使用最少的参数集对其进行独立训练。这样的设计使得可以应用更为非传统的训练方法,比如进化策略,来解决那些在信用分配方面存在重大困难的具有挑战性的强化学习任务。
在高维感官输入的情景下,世界模型利用潜在动力学模型来抽象地表示观察到的信息,从而能够在潜在状态空间内实现紧凑的前向预测。这些潜在状态比直接预测高维数据要高效得多,这得益于深度学习和潜在变量模型的进步,使得可以进行大量的并行预测。例如,在十字路口汽车的方向具有不确定性,这是现实世界动态固有的不可预测性的一个典型场景。潜在变量作为表示这些不确定结果的强大工具,基于当前状态,为世界模型设想的一系列未来可能性奠定了基础。这项努力的关键在于将预测的确定性方面与现实现象的内在不确定性相结合,这种平衡是世界模型效能的核心所在。
4. 世界模型在自动驾驶中的应用与挑战
这一章节主要介绍了世界模型在自动驾驶领域的应用和发展现状。作者提到了多个世界模型的优缺点和应用场景,并分析了当前面临的技术、计算和理论挑战以及伦理和安全问题。同时,文章也指出了未来发展方向和研究重点,包括长期可扩展记忆集成、仿真到现实世界的泛化能力和硬件突破等。
其中提到了一些伦理和社会问题,如隐私保护、数据安全和责任分配等。此外,还探讨了未来可能的发展方向,包括将人类直觉与人工智能精度相结合以及将自动驾驶车辆融入城市生态系统中。最后,强调了需要跨学科合作来解决这些挑战,并确保自动驾驶技术符合社会价值观和安全标准。
5.自动驾驶场景中的应用
自动驾驶数据的获取面临着诸多挑战,包括与数据收集和标注相关的高昂成本、法律限制以及安全考量。世界模型通过自我监督学习范式提供了一种有前景的解决方案,它能够从大量的未标记数据中提取价值知识,从而以成本效益高的方式增强模型性能。
世界模型在驾驶场景生成中的应用尤其值得注意,因为它促进了多样化且真实的驾驶环境的创建。这种能力显著丰富了训练数据集,使自动驾驶系统具备了应对罕见和复杂驾驶情景的鲁棒性。
(1)GAIA-1
GAIA-1代表了一种新颖的自主生成式人工智能模型,能够利用视频、文本和动作输入来创建逼真的驾驶视频。通过Wayve在英国城市广泛的真实世界驾驶数据进行训练,GAIA-1学会了理解一些现实世界的规则和驾驶情景中的关键概念,包括不同类型的车辆、行人、建筑物和基础设施。它可以根据几秒钟的视频输入预测并生成后续的驾驶情景。值得注意的是,生成的未来驾驶情景并不紧密地依赖于提示视频,而是基于GAIA-1对世界规则的理解。GAIA-1的核心采用了自回归变换网络,根据输入的图像、文本和动作令牌预测即将出现的图像令牌,然后将这些预测解码回像素空间。
GAIA-1可以预测多个潜在的未来,并根据提示(例如改变天气、场景、交通参与者、车辆动作)生成多样化的视频或特定的驾驶情景,甚至包括超出其训练集的动作和场景(例如强行驶入人行道)。这展示了它理解并推断不在其训练集中的驾驶概念的能力,同时也证明了它的反事实推理能力。在现实世界中,由于风险性,很难获取这类驾驶行为的数据。驾驶场景生成允许进行模拟测试,丰富数据组成,增强系统在复杂情景下的能力,并更好地评估现有的驾驶模型。
此外,GAIA-1能够生成连贯的动作,并有效地捕捉三维几何结构的视角影响,展现了其对上下文信息和物理规则的理解。结合其展示出的反事实推理能力,可以说GAIA-1在自动驾驶的世界模型方面达到了很高的成就水平,无论是在抽象概念的理解还是因果推理方面。

来源:汽车未来科技Lab













