#03GPU 算力评估
在智能座舱中,显示子系统特别依赖 GPU 的处理能力,同时视觉感知子系统也在一定程度上需要借助 GPU 进行计算。合理评估 GPU 的算力资源,从而判断 SoC 是否能支持座舱内各种显示屏的运作,是一项至关重要的任务。
3.1 GPU 架构原理
从本质上看,GPU是一种基于 SIMD(单指令多数据)架构的计算机系统。与 CPU 相比,GPU 配备了更多的处理单元,并具备更高的并行处理能力,因此能更迅速地处理大量的图形和 图像数据。GPU 之所以适用于并行计算,主要是因为它拥有出色的并行处理能力和丰富的计算单元。GPU 的设计初衷在于提升数据吞吐量,也就是在一次操作中处理尽可能多的数据。为此,GPU 采用了流式并行计算模式,能对每个数据行进行独立的并行计算。这种独特的设计使得 GPU 在处理大规模并发计算任务方面表现出色,例如矩阵乘法、图像处理以及深度学习等。
为了理解 GPU 的工作原理,我们首先需要探究计算机系统是如何绘制并渲染图形的。
从本质上讲,计算机所能处理的图形图像都是由一系列的顶点(Vertex)和纹理(Texture)数据组成的。这些顶点会构成多个三角形,当在这些三角形上贴合相应的纹理后,就能输出用户可见的最终图像。这一过程CPU和GPU的协同工作,以实现最高效率。图2给出了一个图形绘制的流程示意图:
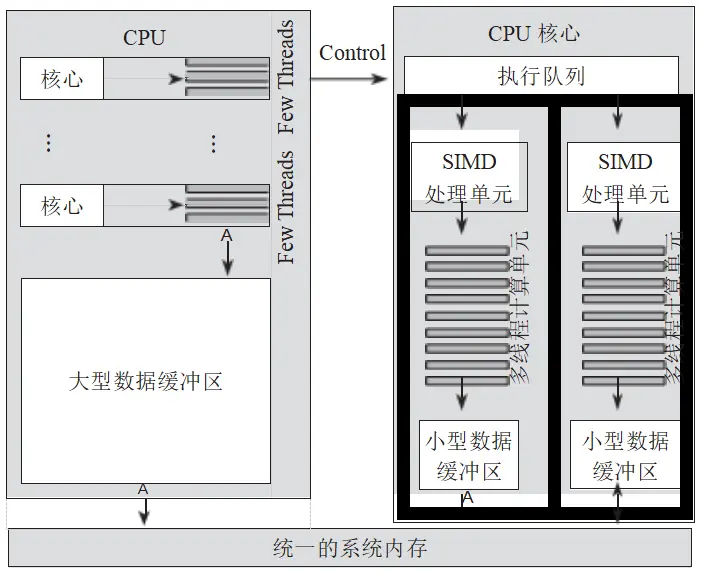
图 11-2 图形绘制流程示意图
绘制过程涉及 CPU、GPU和DPU的共同参与。图形绘制和渲染的核心在于GPU管线(GPUPipeline)。这里的“管线”并非指CPU的并发流水线,而是用来比喻GPU处理图像的流程,就像物品在生产流水线上从一个环节传递到下一个环节,直到全部加工完成。在GPU管线中,图像数据经历一系列的处理步骤,最终输出我们所需的图形图像。表 7 详细列举 了 GPU 管线的主要步骤。
表 7 GPU 管线绘制步骤说明
Early-Z Test
提前深度测试GPU测算每个分块缓冲区域是否被遮挡,提前去掉被遮挡的缓冲区,只处理最顶层应该显示的区块Pixel Shader像素着色器GPU使用渲染的纹理和材质,对每一个像素位图进行填充Raster Operations光栅操作GPU图形渲染的最后一个阶段,经过深度测试和颜色混合后,将生成的像素数据写入GPU的帧缓冲区(framebuffer),然后传送给DPU 进行输出Blender/Output Merger图层混合与输出合并DPUDPU负责实现多图层的合并处理,并输出到显示接口中,如DP 或DSI 接口
在这些操作中,光栅化(Rasterization)和像素着色器(Pixel Shader)是需要进行大量并行处理的关键步骤,要求有足够多的运算单元来执行。因此,在 GPU 的微架构中,这些处理单元被设计为多线程计算单元,以便能够同时处理多个任务,如图 3 所示。
图 3 GPU 并行计算处理单元架构
从图 3 中可以看到 GPU 内部存在一个执行队列。GPU 从这个队列中获取指令,并将其发送到 SIMD 单元执行。SIMD 单元能够调度并执行一条计算指令,同时对多路数据进行处理。计算结果通过数据缓存最终写入系统内存。显然,这种架构非常适合进行矩阵运算或大量像素的并行计算,因为它能够高效地处理批量数据,从而提升整体计算性能。
3.2 GPU 性能评估标准
在智能座舱中,GPU 最主要的用途还是负责图形计算和渲染的任务,它与桌面个人计算机,智能手机的用途一样,首先要考虑图形图像显示的流畅度与画面的精美程度。更进一步, GPU 还要承担 3D 游戏的运行任务,当 GPU 运行压力达到阈值之后,屏幕画面的卡顿、掉帧、降频等问题会严重影响座舱用户的体验。
因此,需要针对 GPU 的性能进行评估,而评估标准既是系统架构工程师选择座舱 SoC 的参考要素之一,也是改进 GPU 性能和评估座舱应用是否可行的依据。
1. GFLOPS
人们习惯使用 GFLOPS(Giga FLoating-point Operations Per Second,每秒 10 亿次浮点运算)作为 GPU 的算力评价标准。我们首先来看一下如何计算GFLOPS。
1 )获取 GPU 的核心数量:核心数量是指 GPU 中包含的核心数量,通常以个为单位。可以通过查询 GPU 的规格或使用 GPU 检测工具来获取核心数量。
2)获取每个核心的频率:每个核心的频率指的是 GPU 的时钟频率,通常 MHz(以兆赫)为单位。可以通过查询 GPU 的规格或使用 GPU 检测工具来获取每个核心的频率。
3 )获取每个核心的浮点运算能力:每个核心的浮点运算能力是指每个核心能够执行的浮点运算数量,通常以 MFLOPS(百万次浮点运算每秒)或 GFLOPS(十亿次浮点运算每秒)为单位。由于核心运行频率的不同,同一个 GPU 架构可能具有不同的峰值运算能力。可以通过查询 GPU 的规格或使用 GPU 检测工具来获取每个核心的浮点运算能力。
4)计算 GPU 的 GFLOPS:使用以下公式计算 GPU 的 GFLOPS:
GFLOPS = 每个核心的浮点运算能力× 核心数量
我们以英伟达的 GeForce 8800 Ultra 芯片为例,计算它的 GFLOPS 参数值。
在 GeForce 8800 Ultra 芯片中,每个SP( Stream Processor,流处理器)核心运行的时钟频率是 1.5GHz( 1.5 × 109 个时钟周期)。
据英伟达公开资料显示,1 个SP核心在1 个时钟周期内的双精度(FP32)的计算能力为3FLOPS,那么 1 个SP核心的峰值算力为:3FLOPS×1.5GHz=4.5GFLOPS Ultra芯片的每个SM(多线程流多处理器)包含8 个SP 核心,SM 运行的峰值算力是4.5 ×8=36 GFLOPS。
GeForce 8800 GPU 一共拥有14个SM ,GPU 的总算力为:36 × 14 = 504 GFLOPS 。
来源:汽车电子与软件
作者:张慧敏













