根据表8 中列出的存储器类型,我们可以看到 CPU 内部的寄存器速度是最快的。如果能全部使用寄存器作为存储器,那么性能无疑将达到极致。然而,由于其高昂的成本,无法大规模采用。另一方面,主存或闪存虽然容量充足且成本适中,但其存取速度相对较慢,无法匹配 CPU 的处理速度。
存储器层次结构的提出,旨在构建一种存储器系统技术,该技术旨在实现每字节成本与主存和闪存相当,而速度则接近最快的寄存器或高速缓存。
在计算机系统结构的设计中,构建这样的存储器系统是切实可行的。
2. 缓存原理
缓存的工作机制是基于局域性原理设计的。局域性原理表明,程序往往会重复使用它们最近使用过的数据和指令块。这里的“最近使用”不仅包含了时间上的局域性,也包含了空间上的局域性。为了充分利用这一特性,在指令预取阶段,处理器会一次性读取一段指令和一块数据。这样,下一条待执行的指令和数据很可能就包含在这已经预先读取的指令段和数据段中。
在常规情况下,指令和数据是保存在主存储器中的。然而,如果将预取的指令和数据保存在缓存中,就可以显著提升 CPU 对存储器中数据的存取速度。这种设计思路正是存储器层次结构的核心所在。通过这种结构,我们能够有效地提升系统的整体性能。图6 展示了一个支持缓存的存储器层次结构。
从图6 可以观察到,主存储器的容量相对较大,但由于其位置离 CPU 较远,访问速度相对较慢。相比之下,缓存离 CPU 更近,尽管其容量较小,却能提供更快的访问速度。CPU 通过高速总线高效地访问存储在缓存中的指令或数据。同时,根据局域性原理,缓存通过低速总线以块传输的方式从主存储器中成批读取指令或写入数据。这样的层次结构设计使得系统仅需增加一小块缓存的成本就能显著提升存储空间的访问速度,同时保持整体存储解决方案的经济性。
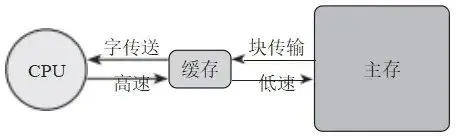
图6 支持缓存的存储器层次结构
3. 缓存优化方法
缓存的设计是一门非常精妙的学问,尽管我们在此不打算深入探讨,但简要介绍其设计思路仍是有意义的。
缓存的设计初衷在于将低速主存中的指令和数据预先提取,并存储在速度更快的缓存中。 当 CPU 需要读取指令或数据时,如果这些数据能从缓存中直接获取,则称之为命中;否则,系统将启动主存预取流程,将一段指令和数据从低速主存迁移到缓存中。这个过程不可避免地会打断 CPU 的流水线操作,从而影响处理效率。因此,命中率,即 CPU 需要从缓存中读取数据时能够直接命中的比例成为了评估缓存性能的关键指标。提高命中率是缓存设计的核心目标,因为它直接关系到系统的整体性能和响应速度。
如何才能提升缓存的命中率?以下是一些可以考虑的方向。
容量:容量越大,则缓存中可存放的数据就越多, CPU 能命中的概率也就越高。
映射:缓存的容量必然不可能达到主存一样的容量大小,否则就不需要设置缓存了。 如何将容量较大的主存映射到容量小的缓存中?这里需要考虑映射算法的设计。现在 最常用的是组相联映射机制,但值得注意的是分组的大小,以及组的数目。不同的选择会带来不同的性能。
替换:一旦缓存存满,当需要装入新的块时,原来的块就需要被替换掉。采用什么样的替换算法才能最大限度地提升命中率?LRU(最近最少使用)、LFU(最不经常使用)、 FIFO(先进先出)、随机算法等,这些都是常用的替换算法可选项。
写策略:缓存中的数据是否需要被写回主存中?SMP 系统中多核如何保证缓存一致性?这些问题都需要通过写策略来进行保证。
行大小:“行”指的是缓存架构中的行,负责从主存中读取数据并存放。主存中的数据 块与缓存中的行相对应。由于局部性原理,CPU 在读取主存中的数据时,不是仅仅读取该数据本身,而是连带读取其周边区域的一整块数据。这些数据将会装入同一个行内。随着行大小的增加,命中率开始上升,但是当行大小达到临界点后,再增加反而会使得命中率降低。其原因在于,较大的行会导致被替换的可能性大大增加,这样可能不得不替换掉不久前刚写入缓存的数据。
分立缓存:最开始的缓存是将指令和数据放在一个缓存中的,这种架构也称为普林斯顿结构。但是现代 CPU 设计引入了超标量流水线架构,它需要支持执行并行指令,预取带预测的指令等功能。此时将指令缓存和数据缓存分开将有利于消除多条流水线带来的冲突。这种分立缓存的架构又被称为哈佛结构。
多级缓存:由于集成电路工艺的提高,缓存与 CPU设计在一块处理器上是非常正常的思路。即使都在一块处理器SoC内部,由于半导体晶体管的特性以及容量大小的区别,缓存的速度也是不同的。相对来说,离CPU越近,则缓存的速度越快。离CPU越远,则缓存速度越慢,但容量可以增大。现代CPU的设计已经开始引入L1、L2、L3 这种 3 级缓存设计。L1 离 CPU 最近,可以跟上处理器的高速时钟频率;L2 和 L3 容量更大,可以提升缓存命中率。
4. 多级缓存架构
根据上述分析,座舱 SoC的存储器层次结构需要综合采用这些可行的方法。由于缓存设计与CPU设计息息相关,它涉及计算机系统结构的核心策略,一般来说由提供高性能CPUIP (知识产权核)的设计公司(如ARM公司等)来提供。现代CPU设计主要采用了3 级缓存的结构,如图7 所示。
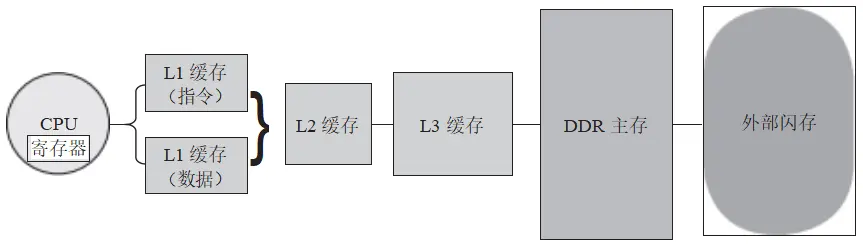
图 7 CPU 3 级缓存设计
从图7 可以看到,存储器之间的速度、容量和价格的权衡。CPU 内的寄存器无疑是速 度最快的存储器,但它的容量非常有限且价格昂贵。通常,一个处理器核心会配备十几个到 几十个这样的寄存器,以确保关键数据和指令能够迅速被 CPU 访问。
主存,通常采用 DDR(双倍速率的动态随机存储器)器件,拥有大容量但速度相对较慢。 它在存储系统中扮演着重要角色,能够存储大量的数据和程序。
在主存和 CPU 之间,设置了 3 级缓存(L1 、L2 、L3 )以提高访问速度。其中,相比 L2和 L3 ,L1 具有更快的速度,但其容量也相对较小。这种设计是为了确保 CPU 能够快速访问最近使用过的数据和指令,从而提高整体性能。
另外,缓存对程序员来说是透明的。这意味着在编写程序时,程序员无须考虑缓存的存在,系统会自动处理缓存的读写操作。这种设计使得编程更加简洁高效,对程序员更为友好。
在设计智能座舱 SoC 时,SoC 的系统架构师通常可以选择 L1 、L2 、L3 缓存的容量大小,在性能和成本之间取得平衡。只有少数自研 CPU 的设计师,才能恰当地设计满足特定需求的缓存内部架构。
5.2 主存储器性能评估标准
在对主存储器性能的评估中,存在两种主要的标准:存储器系统的速率和访问存储器的带宽。
1. 存储器速率评估
作为一个复杂系统, SoC 访问存储器的速率受多个因素的综合影响。
系统架构:不同的系统架构设计对内存访问的性能有着不同的影响。例如,在采用多级缓存的系统中,数据可能需要在不同级别的缓存之间进行传输,这会直接影响访问速度。
DDR 类型:DDR 存在多种类型,如 DDR3 、DDR4 、LPDDR 等,它们的访问速度和性能各不相同。具体来说,DDR4 的访问速度通常快于 DDR3,而 LPDDR 往往比标准 DDR 具有更快的访问速度。
内存大小:内存的大小同样会影响访问速度。一般而言,内存越大,其访问速度可能会相对较慢,这是因为更大的内存意味着控制器需要处理更多的数据位,从而可能增加访问延迟。
内存控制器的优化程度:内存控制器的优化也会对访问速度产生影响。优化不足可能导致访问速度受限,而过度优化则可能增加系统的复杂性,甚至可能影响系统的整体稳定性。
数据传输模式:数据的传输模式同样会影响访问速度。例如,采用突发传输模式可以有效地提升内存访问的效率,进而减少访问延迟。
2. 存储器带宽评估
假设座舱 SoC 采用的主存是 LPDDR5(Low Power DDR v5,第 5 代低功耗 DDR 存储器),我们按如下的条件来计算带宽理论值。
1 )DDR(Double Data Rate ,双倍数据速率)技术:DDR 是 DRAM(动态随机存储器) 的一种类型。DDR 在每个时钟周期的上升沿和下降沿都传输数据,因此每个时钟周期内实际可以传输两次数据。计算 DDR 带宽时,需将时钟频率乘以 2,以得出实际的数据传输速率。
2)等效时钟频率:LPDDR5 的标准核心时钟频率为 200MHz 。DDR 内存的预取数据位通常为 16 位,意味着在每个时钟周期内,DDR 核心会预取 16位数据到I/O缓冲区。因此,有效传输速率为200MHz × 16 = 3200Mbit/s,常用 LPDDR5@3200Mbit/s 表示等效的数据时钟频率。
3 )数据位宽:LPDDR5 的数据位宽由通道数和每通道位宽决定。常见的配置有4通道或8 通道,每通道的位宽通常为16位。因此,8通道 LPDDR5 的数据位宽为 8 × 16= 128 位。
4 )DDR 理论数据传输速率,计算公式如下。

所以,对于 3200Mbit/s 的时钟频率和 128 位的数据位宽,理论传输速率为 3200 × 128 ×2/8 = 100GB/s。注意传输速率是以字节为单位进行计算的。
综上所述,衡量 LPDDR5 带宽速率时,需考虑以下三个关键因素:等效时钟频率(例如 3200Mbit/s)、通道数(可能是 4 或 8)以及通道位宽(根据 DDR 供应链的标准,通道位宽一般都是统一的 16 位)。
DDR 是影响 SoC 性能的关键因素之一,在评估座舱的计算能力时,系统架构师会综合考虑多个方面,通常会将 CPU 、GPU 、NPU 和 DDR 带宽数据一并纳入评估范围。
#06芯片算力评估实例
在详细阐述了座舱 SoC 算力评估的基本原理之后,我们将借助一个具体的实例,深入探讨如何对座舱 SoC 的性能进行准确评估,从而判断 SoC 是否能够满足我们的实际需求。
当主机厂计划引入一颗全新的座舱 SoC 时,进行算力评估是不可或缺的一环。这种评估并非仅仅局限于静态地对比两颗芯片的算力指标,而是需要紧密结合实际使用场景,深入分析和判断新 SoC 在何种程度上能够胜任智能座舱的多元化需求。
6.1 座舱使用场景假设
我们需要对智能座舱的使用场景进行一项假设性分析。
假设在当前的项目中,我们采用的是高通公司的 SA8155 芯片作为智能座舱 SoC。为了满足新一代车型产品的市场需求和性能要求,我们需要评估是继续使用 SA8155 芯片,还是需要替换为算力更高的座舱 SoC?为得到有依据的结论,我们需要先针对新旧两代车型产品的智能座舱功能进行详细的对比分析。表9 列举了座舱的部分使用场景,以便进行评估。
表9 智能座舱使用场景范例
来源:汽车电子与软件
作者:张慧敏











