1. 背景
2. 挑战
3. 引入OASISS:理解数据“完整性”与数据“代表性”
4. 后续工作
1. 背景
人工智能(AI)是当前及未来自动驾驶系统ADS的关键基石。随着 AI 越来越多地应用在自动驾驶这样的安全关键功能,制造商、监管机构和认证机构必须确保这些功能的安全执行。
关于自动驾驶系统的联合国法规(UNR)和全球技术法规(GTR)的制定正在推进,以按计划在2026年中完成,但这两份文件对AI开发和保障的要求关注有限。
WP.29(联合国世界车辆法规协调论坛)已认识到这一点,随后于2025年8月召开了首次会议,启动了一个新的关于AI的非正式工作组(IWG)。然而,该AI IWG的范围比自动驾驶更广,涵盖了汽车领域更广泛的AI应用。标准化论坛也启动了相关活动,近期发布了ISO PAS 8800标准。
2. 挑战
然而,这些活动未能为监管机构评估ADS中所用AI的性能适当性提供工程层面的指导或可衡量的原则。随着多种AI架构和方法(例如,大语言模型、端到端AI、模块化AI等)在ADS生态系统中被广泛使用,任何关于AI开发和保障的指南都需要与技术无关。
每个基于AI的系统都将包含以下开发阶段:
1) 模型创建;
2) 模型训练;
3) 模型测试。
模型训练和测试需要使用“训练”数据和“测试”数据,这是所有AI架构或方法共有的开发需求。
本文档的重点是解决核心问题:“AI系统的训练和测试数据/场景是否充分?”。
通过引入OASISS概念,评估两个关键属性来回答这个问题:完整性和代表性。
3. 引入OASISS:理解数据“完整性”与数据“代表性”
基于ODD的自动驾驶系统中的人工智能安全OASISS(ODD-based AI Safety In autonomouS Systems),旨在支持更广泛的ADS安全保障框架,特别是AI系统的安全保证。
其核心是一种新颖的、与系统无关的评分机制,用于评估训练和测试数据集对于特定目标运行域(TOD)(或称预期运行条件)及系统运行设计域(ODD)的充分性。该框架包含三个核心组成部分,如下图所示。
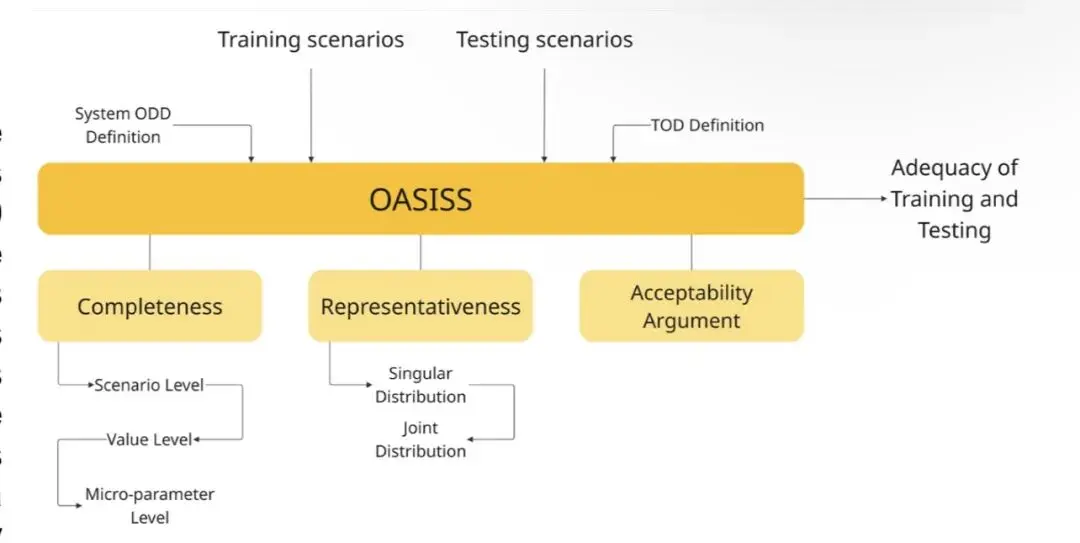
· 完整性评估
· 代表性评估· 可接受性论证
OASISS方法的另一个优势是其与ISO PAS 8800(该标准为道路车辆中执行安全相关功能的AI系统的开发提供指导)保持一致。OASISS采纳了该标准概述的原则,并通过提供一种实用的方法论来实施这些原则,从而扩展了其适用性,特别是在数据集充分性方面。
完整性评估训练和测试数据集是否包含了预期的粒度水平,并考虑了可能的运行条件。然而,即使是“完整”的数据集也不足以保证AI系统训练和测试的充分性。还必须检查数据集的代表性,看其是否反映了现实世界的趋势,确保数据集中的场景与现实中可能遇到的场景相匹配。
为了评估这两个属性,使用运行设计域(ODD)来确定哪些在系统能力范围内、哪些在范围外,并对照目标运行域(TOD)(也称为预期运行条件)进行评估。通过此评估,OASISS提供了一种结构化方法,基于构成每个数据集的场景集合,来确定训练和测试是否真正充分。
OASISS框架图展示了该框架的核心组成部分。前两个部分——完整性和代表性,是对数据集的客观评估。可接受性论证则用于证明在完整性和代表性评估中发现的任何缺陷是合理的。由于OASISS是一个与模型无关的框架,此规定至关重要,旨在供监管或认证机构进行客观评估。
3.1 完整性
通过完整性属性,OASISS旨在评估训练和测试场景集是否能解决以下问题——“系统在其TOD内的表现如何?”以及“系统在其ODD之外的表现如何?”
因此,“一个场景集若包含了其部署区域内会发生的所有运行条件,以及超出系统运行能力的那些条件,则该场景集对于该系统的部署区域而言是完整的。”
OASISS中的完整性组成部分将焦点从这些场景集中的纯粹场景数量转移开,转而使用一个扩展的本体论,对照一个结构化的现实世界表征来系统地评估该场景集。该本体论投射了现实世界的属性,这些属性是场景集根据系统的TOD预期应包含的,以及超出其ODD的条件。数据集根据此本体论进行评分,分数反映了其在多大程度上解决了上面列出的两个关键问题。
对于“超出系统运行能力”的条件,评估期望有一组有限的ODD外场景(非所有可能条件),以验证系统是否被适当地推至其ODD边界以评估其响应,例如发出接管请求或执行最小风险操作(MRM)。如下图所示,完整性评分方法遵循分层方法,在以下层面展开:
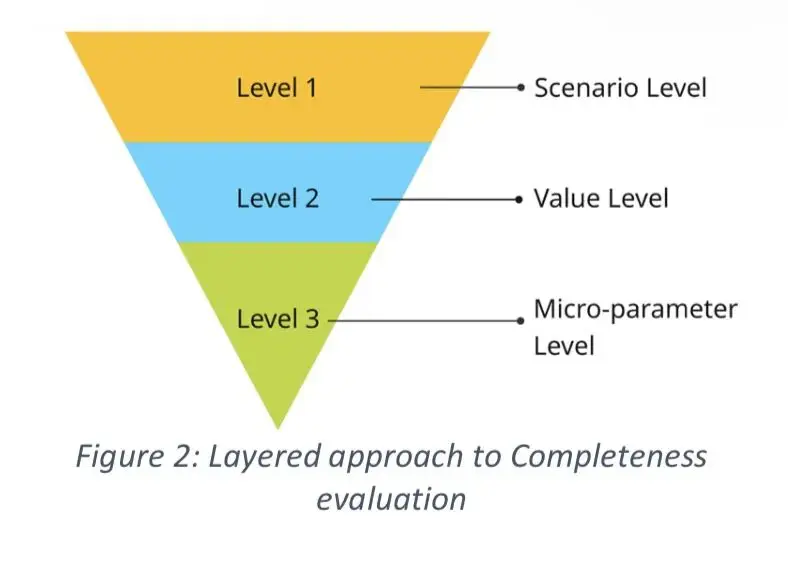
· 场景层面:场景元素(例如,弱势道路使用者VRU)、动态参与者的行为(例如,车辆变道)和时间转换(从ODD内条件移动到ODD外条件)
· 价值层面:场景元素的价值(例如,对于VRU:行人、骑行者、摩托车手等)
· 微参数层面:通常不属于场景描述部分的影响属性(例如,对于行人:衣物类型、身体属性、轮椅、拐杖等)
3.2 代表性
代表性属性确保真实世界的各个方面,直至微参数层面,都在场景集中得到体现。例如,考虑一个已在所有天气条件(大风、雨、雪、雾)下测试过的系统。然而,仔细检查后,我们发现大部分测试包含雨天条件,而其他天气条件的测试很少。如果TOD地区主要下雪,与其他天气条件相比,这就对模型处理各种雪天场景的能力提出了疑问。
这涉及比较场景集中给定运行条件的频率与在TOD中观察到的这些条件的频率。因此,“如果场景集内的场景在单个元素层面和组合元素层面都展现出与该区域内记录的真实世界事件相同或相似的分布,则该场景集代表了系统的部署区域。”
· 单一分布:比较单一元素之间的分布(例如,TOD中的降雨 vs. 场景集中的降雨)
· 组合分布:比较多个元素之间的分布(例如,TOD中夜间降雨 vs. 场景集中夜间降雨)

评估组合分布的代表性依赖于此类组合数据的存在。真实世界试验和事故数据库的记录是此类信息的样本来源,可以从中提取多个参数的出现频率。
有了数据之后,面临的问题是必须评估哪些参数组合。为了将看似无限的组合减少到有限集合,我们依赖领域专家知识。通过分析记录的数据来识别高概率组合,可以增强检测这些组合的过程。此过程也提供了验证专家认为必要的组合是否被数据集捕获的机会。如果没有,则会促使调查数据集是否缺少某些组合,并鼓励审查如何更新数据集以捕获这些额外的组合。
3.3 可接受性论证
可接受性论证是一个将安全论证联系在一起的组成部分,用以证明系统能够处理其预期部署区域内真实世界的运行条件。
OASISS框架认识到每个AI模型都是根据其自身的性能要求和能力进行训练的。因此,该框架允许TOD定义的要求与训练数据集满足的要求之间存在偏差。任何此类偏差都必须经过充分论证,以加强安全论证,旨在弥补场景集与TOD相比所观察到的任何缺陷。
区分此处评估的场景集类型非常重要。训练场景预期应更针对AI模型的要求,这可能导致偏离真实世界,这将自动导致代表性得分较低。
虽然训练集中的这种偏差只要在可接受性论证中得到令人信服的证明是可以接受的,但这并不适用于为验收测试构建的场景集。测试集的场景分布必须与TOD的分布紧密一致,以证明测试足以让AI模型部署在所考虑的TOD中。
4. 后续步骤
OASISS框架贡献了最佳实践,制造商可用其支持更广泛的ADS安全保障框架,并提供了一种潜在的方法论,用以声明训练和测试数据集足以确保AI模型(作为ADS的一部分)在其目标运行区域内的安全部署。
OASISS评估的结果可以指导开发人员识别系统训练和测试相对于其目标运行区域可能被认为不足的领域,同时也为监管和认证机构提供了关于系统在该区域内运行可信度的量化洞察。
引用:Jeyachandran et. al. (2025) Introducing OASISS : ODD-based AI Safety In autonomouS Systems. In: The IEEE International Conference on Intelligent Transportation Systems (ITSC), Gold Coast, Australia, 18-21 Nov 2025 (In Press)
来源:智驾小强













