MSC Nastran是一款功能强大的有限元分析(FEA)软件,是工程仿真的基础。MSC Nastran已被结构分析专家使用和验证了半个世纪,以其稳健性、准确性和能够解决工程中的挑战而闻名。
本期摘要内容
• 了解MSC Nastran如何利用高性能计算(HPC)策略提高您的仿真和分析性能。
• 探索适用于所有分析类型(包括静力学、特征值、动力学和非线性)的可用求解器,以便您可以根据特定的仿真需求选择最合适的求解器。
• 从其他MSC Nastran用户和Hexagon专家的经验中汲取见解,以实现最佳的并行性能,同时最大限度地降低读取和写入磁盘的成本。
• 将HPC专业知识与对MSC Nastran求解器的全面了解相结合,以显著加快仿真速度、最大限度地降低成本并提高不同类型分析的效率。
01 求解器分类
MSC Nastran包含多种求解器。根据分析模型的特点来选择最优的求解器。MSC Nastran 求解器可分为三大类:直接求解器、迭代求解器和特征值求解器。
例如,线性静态分析计算位移和其他结果,其静态仿真性能主要由两步运算决定:求解矩阵方程和将请求的数据写入到输出文件中。为了求解矩阵方程,我们可以使用直接或迭代方法,其中输入是刚度矩阵和载荷,输出是位移。
直接求解器
直接求解器依赖于LDLT分解,该方法在结构分析中应用广泛,这种方法对刚度矩阵的数值特性不敏感,因此适用性比较好,它们的运行过程包含两步。首先,将对称刚度矩阵分解为下三角阵;然后,执行前向消元和后向替换(FBS)来求解结果系统,这一步也称为求解算法的FBS部分。
直接方法利用刚度矩阵中固有的稀疏性(图1)。稀疏矩阵仅意味着有许多零项。多波前Multi-frontal算法利用矩阵稀疏性来减少计算时间和内存需求。
矩阵分解通常占总求解时间的80-90%,而FBS部分通常消耗剩余的10-20%。MSC Nastran 提供三种直接方法:
• MSC稀疏直接求解器(MSCLDL)
• Pardiso求解器(PRDLDL)
• MUMPS求解器(MUMPS 和MUMPSBLR)

图 1:二维稀疏矩阵、非零项以黑色显示(维基百科)
MSCLDL求解器是MSC Nastran的原始稀疏直接求解器,它被设计为在非常有限的内存中运行,但它的并行可扩展性有限。另一方面,Pardiso和MUMPS求解器消耗的内存是MSCLDL的5到12倍,具体取决于模型,但可以表现出更高的性能,尤其是在与共享内存并行(SMP)一起使用时。
迭代求解器
迭代求解器是求解线性方程的另一种选择。迭代求解器的工作原理是使用迭代来减少近似解中的误差,最终在可接受的容差范围内收敛。
迭代方法通常依赖于共轭梯度法或 GMRES算法等技术。尽管这些方法比直接求解器要快得多,消耗的内存也少得多,但它们通常只在某些类型的问题上表现良好,例如载荷工况很少且以实体单元为主导的模型。
特征值求解器
在线性动力学分析中,需要多次动态刚度矩阵的分解。虽然可以基于物理坐标(即物理自由度,相对于模态自由度而言)进行求解,但是它求解效率低,计算时间很长。模态缩减通常用于将系统的物理坐标转换为一组模态坐标,需要计算特征值来获得系统的特征值(和固有频率)和特征向量(振型)。系统的这些内在特性有助于工程师了解其行为,并有助于设计和评估系统在不同条件下的性能。多年来,MSC Nastran 中添加了多种求解特征值问题的方法,包括反幂法(inverse iteration)、Householder、Givens、ACMS和Lanczos 方法。目前,两种最常见的方法是:
• Lanczos 方法
• ACMS(自动部件模态综合法)
Lanczos 方法仅进行必要的计算以找到所需要的根。它使用Sturm序列逻辑来确保找到所有模态。在提取相对较少的特征值时,Lanczos 的大部分计算时间都用于执行对称分解,因此在提高计算效率的策略方面与MSC Nastran中的线性静态分析几乎相同。
ACMS是一种多级模态缩减技术,用于得到正则模态分析结果的近似值。它特别适合于需要提取的模态阶次较多的分析任务,也适用于需要相对较少模态阶数、超大规模模型的求解。将ACMS与FastFR结合使用时,使用模态缩减的频域动态响应甚至更快。FastFR是一种用于模态频率响应运行的加速方法,适用于具有高模态阶数或高激励频率的系统。
接下来,我们将深入研究有关内存、硬件和并行设置的更多细节,以确保求解器以最佳性能水平运行。
02 内存注意事项
使用MSC Nastran进行典型结构的仿真包括线性静态、正态模态、动态响应和非线性分析。当可用内存足够时,求解速度主要受内存带宽的影响。当可用内存不足时,磁盘 (I/O)性能和可用内存成为计算性能的关键决定因素。
内存 (RAM)
大多数直接求解器都允许在In-core或Out-of-core中求解。
1) In-core计算
In-core计算意味着可以将整个数值问题放入到分配的内存(RAM)中。该解决方案速度很快,因为访问内存中的数据比从其他存储介质中检索数据要快得多。
2) Out-of-core计算
Out-of-core计算意味着分配的内存只能进行部分数值方程的求解,因此计算的过程是分批进行的。当数值求解完成一部分时,必须将数据从内存中移出到某个存储介质中,以便为数值求解的下一部分腾出空间。根据所选存储介质的速度,数据的移动将花费一定的时间,而且它比直接在内存中访问数据要慢很多。
在过去几年中,对存储介质的数据访问速度显著得提高。如果配置正确,可以在很大程度上缓解与写入存储介质相关的延迟,但分批解决out-of-core的问题始终会降低性能。无论以何种方式解决问题,求解过程都会生成临时数据,这些数据仅用于管理求解过程。如果有足够的内存可用,则此临时数据也可以存储在内存中的缓冲区中。如果内存不足,则必须将其写入其他存储介质。给任何大规模求解计算分配内存将始终影响求解性能。操作系统有自己的I/O缓冲逻辑,但最好使用通过MSC Nastran缓冲池提供的缓冲系统。
为了简单地说明MSC Nastran如何使用内存,让我们忽略MSC Nastran分配给其执行系统的少量内存。MSC Nastran在计算时基本上设置了两个重要的内存区域:主要区域称为open core,也称为 HICORE;另一个重要区域分配给缓冲池,它的名称为BPOOL。
图2说明了MSC Nastran如何为各种任务分配内存。提交计算时,MSC Nastran会使用用户指定的计算机上总物理可用RAM的一部分。如果在提交过程中使用“mem=max”命令,MSC Nastran 将使用计算上50%的可用物理内存。此内存大小,一部分分配给缓冲池系统 BPOOL,另一部分分配给求解器 HICORE。
• BPOOL使用内部缓存算法。增加BPOOL的大小会减少对磁盘型存储介质的读写。这对于具有高I/O需求的大问题特别有用,在I/O配置较差的计算机上可以显著的提高运行时间。另一方面,BPOOL分配的内存越大,HICORE就会越小。
• HICORE表示求解计算而分配的内存。
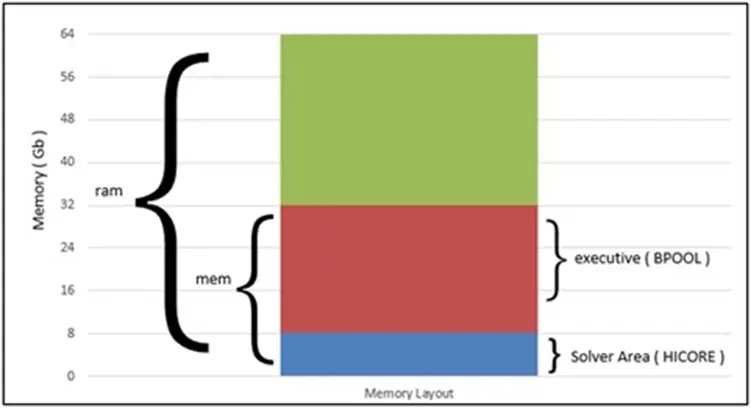
图2:MSC Nastran求解的内存布局
图3展示了一个200万自由度(DOF)系统在三台机器上进行静态接触分析计算(SOL 101)的示例。这些计算机具有相同的硬件配置,但安装的RAM内存大小分别为16GB、64GB和128GB。
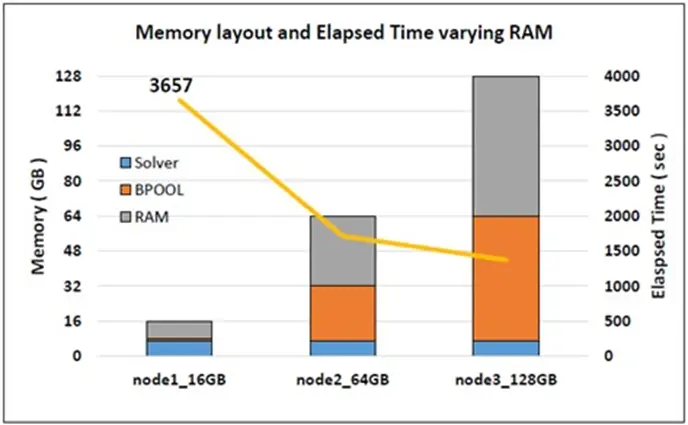
图3:不同RAM的内存布局(条形图)和性能(黄线)示例
对于此模型,将内存从16 GB增加到64 GB可使运行时间减少53%。将RAM增加到128 GB后,运行时间总体上减少了63%。请注意,分配给求解器(HICORE)的内存量保持不变(以蓝色显示),而BPOOL的大小会发生变化(以橙色显示)。增加BPOOL的大小可以减少运行时间,因为关键数据缓存在BPOOL内存中,并且I/O运算显著加快。
内存分配一般建议是在MSC Nastran提交计算命令行上使用 memory=max。这会将计算机的50%的物理内存分配给作业,并根据模型大小、特性和可用RAM将此数量分配给求解器和缓冲池。
来源:海克斯康工业软件






