编者按:该论文提出了首个基于连续视觉感知的具身空间推理框架Embodied-R,旨在赋予预训练模型具身空间推理能力。论文通过强化学习和大小模型协同,将训练推理范式拓宽至具身智能领域,其中大规模视觉语言模型用于感知任务,配合小规模语言模型进行高层次推理,从而高效地实现复杂的空间理解。论文设计了一种全新的奖励机制,强调“思考-回答”的逻辑一致性,并基于强化学习进行训练,使模型能够在计算资源有限的情况下展现出“慢思考”能力。实验表明,Embodied-R在多个空间推理任务中达到了与OpenAI-o1、Gemini 2.5-pro等主流多模态模型相媲美的表现。
本文译自:
《Neural network vehicle models for high-performance automated driving》
文章来源:
arxiv preprint
作者:
Baining Zhao, Ziyou Wang, Jianjie Fang, Chen Gao, Fanghang Man, Jinqiang Cui, Xin Wang, Xinlei Chen, Yong Li, Wenwu Zhu
作者单位:
清华大学
原文链接:
https://arxiv.org/abs/2504.12680
摘要:人类可以通过连续的视觉观察(如第一视角的视频流)来感知和推理空间关系。然而,预训练模型如何获得这类能力仍不清楚,尤其是高层次的推理能力。本文提出Embodied-R,一个结合了大规模视觉-语言模型(VLMs)用于感知和小规模语言模型(LMs)用于推理的协同框架。该框架采用强化学习(RL)进行训练,引入一种新的奖励机制,并考虑“思考-回答”的逻辑一致性,使模型在计算资源有限的情况下具备慢思考能力。在仅使用5000条具身视频样本进行训练后,具有30亿参数语言模型的Embodied-R在分布内和分布外的具身空间推理任务上,都达到了与最先进的多模态推理模型(OpenAI-o1,Gemini-2.5-pro)相当的表现。Embodied-R 还展现出了系统性分析和上下文整合等新兴的思维模式。我们进一步探讨了一系列研究问题,包括:回答长度、VLM训练、奖励设计策略,以及在有监督微调(SFT)与强化学习训练后模型泛化能力的差异。
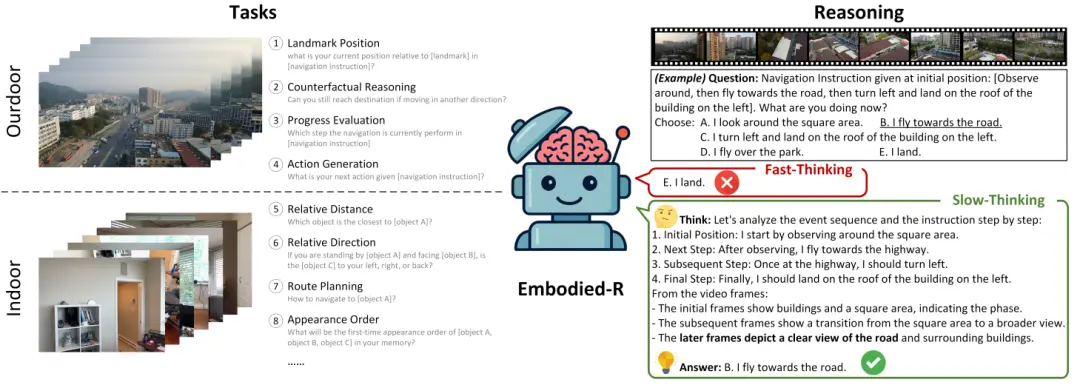
图1. 具身空间推理:任务和思维过程。确定了来自公共嵌入式视频数据集的具有挑战性的任务,包括室内和室外场景。我们引入慢思维来提高推理性能
1 引言
在通往通用人工智能 (Artificial General Intelligence, AGI)的道路上[17],我们希望预训练的基础模型不仅可以在网络世界中执行对话和图像理解等任务[2,44],而且还在三维物理世界中发展出类似人类的具身空间认知,使他们能够感知、思考和移动[4,32]。人类实现空间认知的基本方式是通过连续、动态的视觉观察,类似于视频流 [26,30]。例如,通过观察周围环境,人类可以推断出他们相对于附近物体的位置。同样,基于历史的视觉观察,人类可以确定到达目标目的地应该采取的行动。
视觉空间认知可以分为两个层次:感知和推理[51]。感知是指“所看到的”,其特征是直接的、低级的任务,如物体识别、边缘检测或颜色区分[52]。而推理涉及“所理解的”和“要采取的行动”,这是需要逻辑推理和知识间接整合的更高层次的任务[62]。推理的例子包括“我从哪里来?“(回忆历史运动轨迹[36]),”我在哪里?(推断附近物体和距离之间的空间关系 [5])和“我想去哪里?(规划行动和决定到达目的地的移动方式[8])。虽然现有的大多数研究都集中在提高基础模型的感知能力上[6,11],并取得了显著的进展,但它们的空间推理能力仍然有限[9,58],并且增强方法在很大程度上尚未探索。
具体来说,基于视频的空间推理带来了以下几个挑战:
-
推理总是建立在感知之上 [19,32]。对于所研究的问题,连续的视觉观察对感知提出了更高的要求。通过错误的感知或幻觉无法很好地实现推理 [53]。当对视频的感知变得困难时,很难进行推理。
-
视频数据自然涉及复杂的时空关系,需要发现跨帧的对象关联并提取与推理任务相关的语义[16]。例如,要导航到当前视野之外的目的地,必须从历史视觉观察中推断出它们的位置,构建环境的心理地图,制定一个高级规划来确定方向,最后决定要执行的具体行动。现有的有监督微调 (supervised fine-tuning,SFT) 训练方法缺乏对推理过程的监督,难以处理此类推理任务[62]。
-
具身视觉观察具有鲜明的特征。首先,对于非具身视频(如电影或电视节目)的理解,主要强调的是视频内容本身,通常从宏观且客观的视角进行分析[27]。相比之下,以自我为中心的视频则更关注观察者与周围环境之间的关系,通常是从受限的第一人称视角进行理解 [22]。其次,具身连续视觉观察是在时间维度上持续生成的,这表明具身感知应依赖于时序输入,而非在较长时间后将所有视觉观测统一聚合为单一输入[31]。最后,由于物理世界中运动的连续性,第一视角视觉观察同样表现出空间上的连续性,即帧与帧之间存在大量冗余和重复。因此,直接将现有的多模态大语言模型(multimodal large language models,MLLMs)应用于具身视频时,会导致包括泛化能力下降和由于冗余帧过多而引发的输入token限制等问题[1, 29]。
最近,OpenAI的o1/o3[38]和DeepSeek-R1 [24]在解决复杂推理问题(例如数学、编码、科学等)方面的出色表现引起了人们对强化学习 (reinforcement learning, RL) 技术的关注。通过将思维链 (chain-ofthought, CoT) 推理过程纳入训练后,大型语言模型 (large language models, LLM) 展示了一种“慢思考”模式,即它们在生成响应之前会进行彻底的推理[45, 55]。受此启发,我们尝试将 “慢思考” 引入基于视频的具身空间推理任务中,如图1 所示。
这带来了一个新的挑战:模型大小和计算成本之间的权衡。现有研究表明,多模态理解和感知能力与模型大小之间存在很强的相关性[7, 20, 56]。由于推理建立在感知的基础上,因此应使用更大的视觉语言基础模型作为训练的起点。然而,增加模型尺寸通常会带来不可接受的计算成本。此外,视频输入映射到长token序列,进一步提高了计算需求。有没有办法利用大规模模型的感知能力,同时以较低的计算成本发展具身推理能力?
受此启发,本文设计了一个协同框架,包含两个主要组成部分:用于感知的大规模视觉语言模型 (vision-language model, VLM) 和用于推理的小规模语言模型 (language model, LM) 。基于观测的连续性,我们首先提出了关键帧提取器,以保留关键信息并降低计算成本。使用VLM对帧序列逐步提取语义信息,从而模拟真实世界中的在线推理过程,并有效控制VLM在处理长视频输入时的输入token长度。最后,将语义信息与推理问题共同输入到小规模语言模型中,输出推理过程及最终答案。小规模语言模型通过强化学习 (reinforcement learning, RL) 进行训练,其中奖励建模不仅结合了受Deepseek-R1Zero [24] 启发的基于规则的奖励,更重要的是为推理过程引入了一种新的逻辑一致性奖励。在实验部分,我们围绕七个研究问题展开,涵盖了该框架的性能、强化学习在激活具身空间推理中的作用以及分布外泛化能力等方面。
总结来说,本文的主要贡献如下:
-
我们提出了一个用于大规模和小规模基础模型的协作框架,以解决视频模态中的空间推理问题。通过解耦感知和推理,该框架利用了大规模基础模型的感知能力,同时以计算资源友好的方式有效地增强了较小模型的推理能力。
-
这是首次采用强化学习 (reinforcement learning, RL) 来增强基础模型的具身空间推理能力的工作。具体来说,我们引入了一种新的逻辑一致性奖励,它提高了推理过程和生成的答案之间的一致性。
-
我们提出的 Embodied-R 在分布内与分布外基准测试上均取得了与最新多模态大语言模型(如 OpenAI-o1/Gemini-2.5-Pro)相当的性能表现。我们还进一步探讨了包括基于SFT与RL训练的模型在泛化能力上的对比、奖励设计策略等多个研究问题。
2 相关工作
大语言模型推理。近年来,增强推理能力已成为大型模型技术的一个关键研究方向,并在数学和逻辑问题求解等任务上展现出卓越的表现 [25, 47, 57]。随着 OpenAI 发布o1模型 [38] 后,大量研究提出了各种技术方法以实现类似功能,包括思维链(Chain-of-Thought, CoT)[54]、蒙特卡洛树搜索(Monte Carlo Tree Search, MCTS)[23, 60]、知识蒸馏(distillation)[35]、结合监督微调(SFT)或直接偏好优化(DPO)的拒绝采样(rejection sampling)[40] 等。此外,Deepseek-r1 [24] 提出了一种通过基于规则的奖励机制结合强化学习来促进大语言模型(LLMs)推理能力涌现的方法。同样地,Kimi k1.5 [45] 提出了类似的思路,并介绍了一系列训练技术,例如课程学习(curriculum learning)。这种强化学习范式引发了广泛关注,后续的研究也成功复现了相关成果[55, 59]。
VLMs具身空间推理。 受基础模型在多个领域中表现出的通用性启发[2, 3],具身智能旨在开发能够利用大型多模态模型作为“大脑”的智能体,以实现在三维物理世界中的感知、导航与操作能力[15, 41]。从输入角度来看,人类的视觉-空间感知更接近于连续的RGB观测数据,类似于视频流[12, 42],而不是静态图像[48]或点云[52]。一些具身视频基准测试[58] 表明,尽管感知类任务已经相对较好地被解决,但诸如空间关系推理、导航和规划等空间推理任务仍然极具挑战性。然而,目前关于视频推理的研究[16, 43]主要集中在非具身的内容推理上,对涉及具身连续视觉输入的场景关注较少。
大模型和小模型之间的协同。 当前的研究主要聚焦于解决大模型带来的资源消耗和隐私风险问题,以及小模型在特定场景下的效率和性能优势[50]。小模型可以在数据选择、提示优化和推理增强等方面辅助大模型[28, 61]。文献[49, 63]探索了使用小模型检测幻觉和隐私泄露的方法,从而提升整个系统的可靠性。虽然我们的工作也以降低计算资源需求为目标,但我们强调大规模VLM在感知方面的作用,以及小规模LM在增强具身空间推理中的互补作用,这与其他研究有所不同。
3
Embodied-R模型
我们首先定义具身空间推理的问题。随后,我们介绍了基于视觉-语言模型(VLM)的感知模块和基于语言模型(LM)的推理模块。协作框架如图2所示。
3.1问题建模
在现实物理世界中,智能体在空间中移动,生成一系列视频帧(连续的视觉观测数据)。假设一个空间推理问题表示为。我们的目标是构建一个模型,以和作为输入,并输出答案。如果答案在语义上与真实标签一致,则认为该答案正确;否则视为错误。
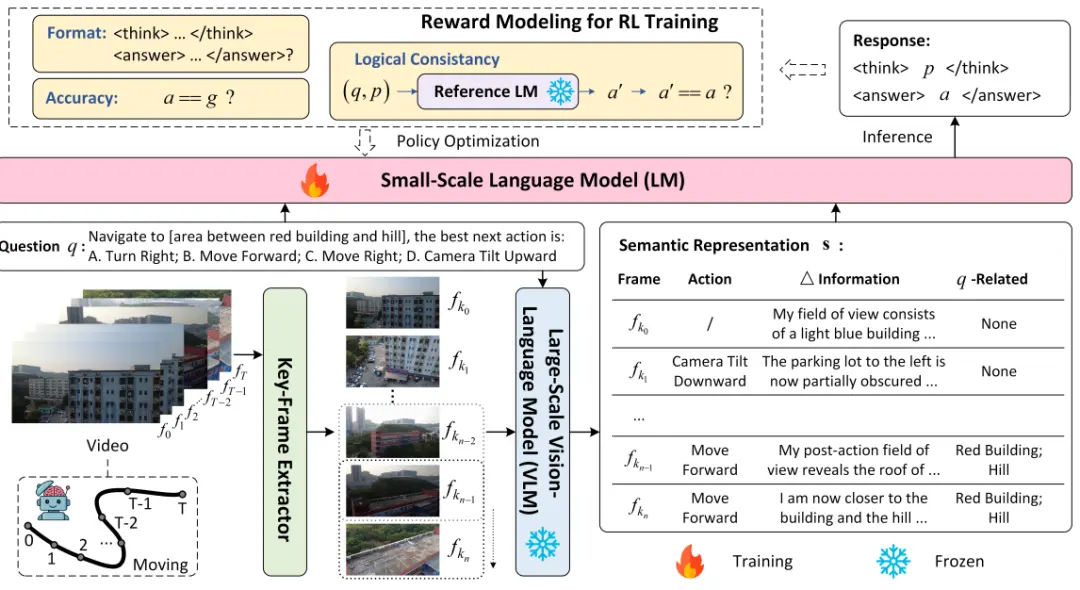
图2. 所提出的Embodied-R是一个集成了视觉语言模型(VLM)和语言模型(LM)的协作式空间推理框架。感知和推理的分离使我们能够利用大规模VLM的感知能力,同时训练资源高效的小规模LM,通过RL激活具身推理。值得注意的是,我们引入了一种新的逻辑一致性奖励,以指导LM产生逻辑连贯的推理和答案
3.2 基于大规模VLM的感知
3.2.1 关键帧提取器
当智能体在空间中持续移动时,若采样频率较高,会导致相邻帧之间存在显著重叠。一方面,VLM 依赖于环境中静态物体在不同帧之间的变化来推断智能体的姿态变化;另一方面,过多的帧间重叠会增加 VLM 和 LLM 的推理成本。为了解决这一问题,我们设计了一个针对具身视频特性的关键帧提取器,能够在保留一定重叠度的同时,选择信息增益足够的关键帧。
关键帧的提取基于运动连续性所导致的视野重叠。当智能体向前移动时,后一帧中的视觉内容预期会与前一帧的部分区域重叠;向后移动时则相反。同样地,在向左或向右旋转时,后一帧应在水平方向上与前一帧部分重叠;在向上或向下旋转时,重叠则发生在垂直方向上。由于视觉观测的采样频率通常远高于智能体的运动速度,因此帧之间普遍具有较高的重叠度。
具体而言,我们使用透视变换来建模帧之间的几何关系。假设是一个关键帧,为了判断是否也应被视为关键帧,我们使用带方向的 FAST 关键点检测和旋转 BRIEF 描述子(Oriented FAST and Rotated BRIEF, ORB)算法从和中提取关键点及其描述子。接着,使用特征匹配算法(如暴力匹配器 Brute-Force Matcher)对这两帧之间的描述子进行匹配,并通过随机采样一致性算法(RANSAC)估计单应性矩阵,从而计算两帧之间的重叠比例。如果该重叠比例小于预定义的阈值,则表明帧之间存在显著的视觉变化,因此将 标记为新的关键帧;否则,算法将继续计算与之间的重叠比例。这一过程持续进行,直到识别出一个新的关键帧,随后该帧将成为后续帧的参考基准。考虑到视角变化的影响,水平或垂直方向的旋转会导致更大的视野变化,从而在这些运动过程中记录更多的帧。若提取出的关键帧索引表示为,则关键帧提取过程可总结为:
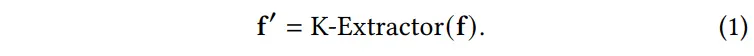
3.2.2 具身语义表示
由于感知能力通常与模型规模正相关 [27, 58, 62],我们采用大规模VLM来处理视觉输入以确保高质量的感知效果。每个关键帧的差异信息被依次描述。这种方法带来了两个主要优势:1)顺序化、动态化的处理方式更符合具身场景的特点:在具身智能中,视觉观测是随时间连续生成的。在每一个时刻,模型都应能融合历史语义表示与最新的视觉观测,快速更新对空间感知的语义理解。2)它有助于处理长视频内容,避免了因输入token数量限制而带来的问题,这些问题在直接处理长序列时常常成为瓶颈。
具体而言,对于第一帧,VLM会识别场景中存在的物体、它们的属性以及空间位置。对于后续各帧,则将前一帧和当前帧同时输入 VLM,以提取关键语义表示 :
 其中,包含以下三个组成部分:
其中,包含以下三个组成部分:
-
动作(Action):基于连续帧之间视觉观测的变化,推断智能体所执行的动作。
-
变化信息(Information):确定智能体与已知物体之间的空间关系变化,并判断视野中是否出现了新的物体。
-
与问题相关的内容(
来源:同济智能汽车研究所













