智能汽车是汽车、电子、信息通信、道路交通运输等行业深度融合的新型产业形态。当前, 我国智能汽车产业进入快车道, 技术创新日益活跃, 新型应用蓬勃发展, 产业规模不断扩大,而相应的测试技术体系也在不断完善, 推动产业进步。本书首先立足于整体现状对智能汽车测试体系架构进行综述, 并针对测试技术的发展趋势和整个核心技术进行详细描述;然后, 针对测试体系中每一测试过程的概念、核心思想、关键技术、测试方法、发展趋势等进行详细描述。
注:本文节选自《智能汽车测试技术》第五章节,由机械工业出版社于2025年6月份出版
https://mp.weixin.qq.com/s/MlQwkx8HzGRqa4meVhUteQ
《智能汽车测试技术》目录
第1 章
导论
1.1 背景与需求/ 001
1.2 基本概念/ 003
1.2.1 测试与评价的基本概念/ 003
1.2.2 产品全生命周期中的测评技术/ 004
1.3 现状与挑战/ 005
1.4 本书章节安排/ 006
第2 章
智能汽车
测评概述
2.1 测评需求分析/ 009
2.1.1 安全性测试与验证/ 009
2.1.2 智能性测试与评价/ 012
2.2 测试方法论/ 015
2.2.1 安全性测试验证框架/ 015
2.2.2 智能性测试评估框架和体系/ 017
2.3 测试工具链及应用要求/ 023
2.3.1 测试工具链/ 023
2.3.2 测试需求与测试工具的适配性/ 027
2.4 本章小结/ 029
参考文献/ 030
第3 章
智能汽车
测试场景
3.1 场景基本概念/ 031
3.2 场景体系/ 033
3.2.1 场景要素与属性/ 033
3.2.2 场景层级/ 035
3.2.3 场景分类/ 036
3.3 场景生成方法/ 037
3.3.1 基于形式化描述的场景生成方法/ 037
3.3.2 基于驾驶员模型的场景生成方法/ 040
3.3.3 安全关键场景生成方法/ 048
3.4 场景采集与利用/ 051
3.4.1 场景采集技术/ 051
3.4.2 场景库搭建/ 052
3.5 本章小结/ 052
参考文献/ 053
第4 章
环境感知
系统的测试
技术与方法
4.1 环境感知系统测试需求分析/ 055
4.2 环境感知系统介绍/ 057
4.2.1 感知系统/ 057
4.2.2 硬件模组/ 058
4.2.3 认知算法/ 058
4.3 环境感知系统测试技术框架/ 059
4.4 各类感知环境介绍/ 060
4.4.1 封闭场地环境/ 060
4.4.2 道路交通环境/ 064
4.4.3 虚拟仿真环境/ 066
4.5 数据生成模型介绍/ 069
4.5.1 降雨图像生成方法概述/ 070
4.5.2 降雨图像生成模型介绍/ 071
4.5.3 降雨图像生成模型结果/ 075
4.6 具体测试案例/ 076
4.6.1 案例一:基于封闭场地环境的感知系统测试/ 076
4.6.2 案例二:基于虚拟仿真环境的硬件模组测试/ 078
4.6.3 案例三:基于虚拟仿真环境的感知系统测试/ 081
4.6.4 案例四:基于三类感知环境和数据生成模型的
认知算法测试/ 083
4.7 本章小结/ 086
参考文献/ 087
第5 章
决策规划
系统的测试
技术与方法
5.1 决策规划系统的测试需求与挑战/ 089
5.1.1 测试需求/ 089
5.1.2 测试挑战/ 090
5.2 基于场景的测试技术与方法/ 092
5.2.1 静态试验设计测试方法/ 092
5.2.2 动态试验设计测试方法/ 094
5.3 基于真实里程的测试技术与方法/ 101
5.3.1 开放道路测试技术/ 101
5.3.2 重要度采样加速测试方法/ 103
5.4 基于虚拟里程的测试技术与方法/ 104
5.4.1 虚拟里程测试系统组成框架/ 105
5.4.2 用于虚拟里程测试的NPC 模型生成方法/ 106
5.4.3 用于虚拟里程测试的NPC 模型性能验证/ 113
5.4.4 虚拟里程测试的应用/ 118
5.4.5 小结/ 130
5.5 其他测试技术/ 131
5.5.1 自动化测试技术/ 131
5.5.2 错误注入测试技术/ 139
5.5.3 分布式自动化测试技术/ 152
5.6 本章小结/ 157
参考文献/ 157
第6 章
整车测试
技术与方法
6.1 整车测评需求分析/ 159
6.2 封闭测试场地平台/ 160
6.2.1 封闭测试场/ 160
6.2.2 动态模拟目标物系统/ 162
6.2.3 定位与数据采集系统/ 163
6.3 开放道路测试系统/ 164
6.3.1 测试方案制定/ 165
6.3.2 数据采集与数据闭环系统/ 165
6.4 本章小结/ 166
第7 章
智能汽车
安全性评估
7.1 基于具体场景的安全性评估/ 169
7.1.1 场景瞬时风险评估方法/ 170
7.1.2 多阶段安全评估/ 180
7.1.3 单个测试场景结果外推/ 181
7.2 基于逻辑场景的安全性评估/ 182
7.2.1 评估要求/ 182
7.2.2 面向逻辑场景评价的危险域识别方法/ 183
7.3 针对被测功能的安全性评估/ 192
7.4 本章小结/ 192
参考文献/ 193
第8 章
智能汽车
综合行驶
性能评估
8.1 测评需求与研究现状/ 195
8.1.1 测评需求/ 195
8.1.2 研究现状/ 195
8.2 测评基本流程/ 197
8.3 典型测试场景矩阵/ 198
8.4 测试方法与流程/ 199
8.4.1 测试方案/ 199
8.4.2 背景车跟驰模型/ 199
8.4.3 测试数据输出/ 201
8.5 评价方法与流程/ 202
8.5.1 评价体系/ 202
8.5.2 评价流程/ 204
8.6 测评示例/ 206
8.7 本章小结/ 209
参考文献/ 209
附 录
附录A 测试工况参数设置/ 210
附录B 背景车跟驰模型/ 212
附录C 归一化方法/ 214
附录D 常见缩写词/ 216
用于虚拟里程测试的NPC 模型生成方法
虚拟里程测试的测试性主要来源于被测系统与背景车辆的交互, 用于背景车行为决策的NPC 模型的性能直接决定了虚拟里程测试的效果。因此需要通过合理的模型生成方法完成NPC 模型的构建, 使其具备真实性、测试性等性能,从而保证虚拟里程测试系统的测试效果。
能够用于NPC 模型构建的方法有很多, 可以通过规则或效用函数构建模型, 也可以采用模仿学习、强化学习等机器学习方法, 采用不同方法生成的模型可以根据其行为能力进行分级。基于规则的驾驶员模型以及各类模型的分级方法已经在本书的3.3.2 节中进行了介绍, 在本节中将对机器学习方法中的强化学习和模仿学习进行简单的介绍, 并对各类方法的优劣势进行简单分析。
1 . 强化学习
强化学习问题可以简述为, 通过奖励函数设定目标让智能体在环境中进行策
略优化, 使得执行策略获得的长期奖励值达到最优。在虚拟里程测试系统的NPC模型训练过程中, NPC 模型即为被训练的智能体, 其首先对环境进行观测, 获得当前观测状态si , 然后根据当前策略选定并执行动作ai , 并计算奖励ri 反馈给智能体, 最后根据奖励对智能体策略进行更新, 使得策略收敛到接近最优, 如图5 -18 所示。这一过程可以用公式表示为
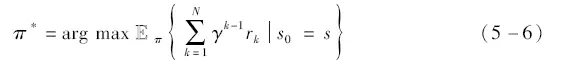

图5 -18 强化学习框架
式中,k为训练过程中的迭代步数;γ为奖励折扣因子;rk为第k步迭代获得的奖励值。
奖励函数是根据模型的训练目标进行设计的,反映了模型所具有的目标特征。而用于强化学习模型训练的数据来自训练过程自身,因此其对数据的依赖性很低。在用于训练的数据中,模型行为的评价是通过对奖励函数的计算进行的,因此模型的性能与奖励函数的设定紧密相关,具有较强的可解释性。然而由于仅采用奖励函数的设定较难覆盖所有驾驶工况,无法对驾驶行为进行100%还原,因此采用强化学习方法生成的驾驶员模型在真实性上的表现相对较差。
根据训练环境和奖励函数的设置不同,强化学习生成的模型又可以分为对抗模型和非对抗模型,二者在模型特征上具备一定的区别。
(1)对抗模型
NPC模型与SUT的交互是关键场景的生成来源,而其中NPC模型的对抗性行为可以提升交互过程中关键场景的出现概率。为了提升关键场景的生成效率,通过强化学习训练NPC模型时,可以对模型的对抗行为进行训练,获得的模型可以称为对抗模型。
通常通过对训练环境和奖励函数进行对抗性设定以获取对抗模型。在训练对抗模型时,通常将SUT接入训练环境中进行训练,使得在训练过程中就存在NPC模型和SUT的交互行为;在奖励函数上,通过设定与模型对抗相关的奖励函数,对与关键场景生成相关的对抗行为给予正奖励反馈,会使得NPC模型有更大的概率选择这部分对抗行为,从而提升虚拟里程测试过程中背景车与SUT对抗行为的出现概率,加速关键场景的生成。
根据上述内容可知,由于对抗性设定的存在,对抗模型在测试性上的表现最好;但由于训练时在训练环境和奖励函数的设定具有一定的局限性,因此对抗模型在真实性和演化性的表现上相对较差,部分模型可能只在特定场景下具有较好的测试效果。
对基于强化学习的对抗模型,代表性的研究见表5-3。
表5-3 强化学习对抗模型论文
 (2)非对抗模型
(2)非对抗模型
通过强化学习训练NPC模型时,如果奖励函数中只包含对模型自身驾驶特性的奖励,且训练环境中不包含SUT,则在进行仿真时此类模型与SUT的对抗特性较弱,可以把这类模型叫作非对抗模型。
此类模型在训练过程中不存在与SUT的交互,在模型训练完成后再接入SUT进行在环仿真测试,奖励函数也不会对于车辆之间的对抗行为给予正奖励,因此其在决策时只会考虑自车的行驶特征收益。在训练时自车行驶特征通常可以包括跟车、换道行为的真实性,以及自车对于行驶空间的追求程度等信息,所有的奖励都是服务于自车的行驶能力,所以通常模型具有很强的演化性和一定的真实性,能够在多种道路拓扑和不同场景中表现出良好的适应性;而由于没有对抗性的特殊设定,因此其作为背景车时的测试能力通常不够强。
对于非对抗模型,可以对其特性进行差异化设计,获取具有异质特性的模型。由于人类的操纵决定了其驾驶车辆的行驶特征,因此不同驾驶员的驾驶特征存在差异。异质化的驾驶员模型设定可以更好地模拟真实交通环境,并可以通过修改模型占比,提升虚拟里程测试系统的测试效果。
从驾驶风格上,可以将模型分为普通型、保守型、激进型。对于保守型驾驶员模型,通常代表驾驶能力较弱、驾驶经验欠缺的驾驶员,该类驾驶员较少做出换道或急加减速等动作。激进型驾驶员模型通常是造成危险场景的原因,因此受到了较多研究者的关注。该类驾驶员模型通常倾向于做出有一定风险性的驾驶行为,具有较高的平均车速、平均加速度和较短的跟车车头间距;高频的急加/减速和换道动作。
从交互属性上,可以将模型分为中立型、合作型、竞争型。对于中立型驾驶员模型,只关注自车的行驶收益,因此建模目标只包含对自身行驶质量的量化指标。合作型驾驶员模型在关注自身行驶收益的前提下,会考虑可视范围内其他车辆的行驶收益,以体现合作特性。竞争型驾驶员模型在关注自身行驶收益的前提下,会压缩周围其他车辆的行驶收益,以体现竞争特性。
对基于强化学习的非对抗模型,代表性的研究见表5-4。
表5-4 强化学习非对抗模型论文

2. 模仿学习
模仿学习(ImitationLearning),顾名思义,就是要通过训练让模型学习专家数据的动作,使得模型能够面对环境状态输入做出与人类驾驶员相似的动作,从而达到模仿的目的。在难以设计奖励函数,但具备专家示范数据的训练场景下,采用模仿学习的方法通常可以获得较好的NPC模型训练效果。
常见的模仿学习方法主要有两种:行为克隆(BehaviorCloning)和逆强化学习(InverseReinforcementLearning,IRL)。行为克隆是一种直接从专家数据中学习策略模型的方法;而逆强化学习从专家数据中学习数据背后隐含的奖励函数(RewardFunction),并根据奖励函数来训练最优的驾驶策略,这是两种方法的主要区别。
(1)行为克隆
采用行为克隆方法进行训练时,专家数据通常会被以“状态-动作”对的形式进行输入。其中状态通常为NPC模型周围的环境观测信息,作为模型的输入信息。在NPC模型根据状态做出决策之后,决策结果会与专家数据中的动作信息共同输入到损失函数中,并通过策略梯度更新策略模型,从而不断逼近损失函数的最小值,实现模型决策对专家数据的“克隆”。
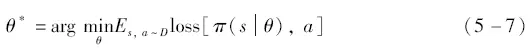
式中,π为训练的NPC模型策;θ为策略参数;s和a分别为专家数据中的状态和动作信息;loss为损失函数。通过对比策略π对状态s的输出动作和专家数据中的动作a之间的差异,对策略不断进行更新,从而使得损失函数达到最小值。
由于训练数据完全来自输入的专家数据,因此行为克隆能够很好地学习到专家数据的行为,生成的模型具备很好的真实性;且由于数据均为训练前处理好的,因此在训练过程中不再需要收集和处理数据的工作,生成效率较高。但这项特征也同时导致了其演化性和测试性差的特点:一旦模型遇到没有经过专家数据训练的状态,将可能会做出不安全的驾驶行为;与关键场景生成相关驾驶行为的专家数据也很难获取,因此训练获取的模型用于测试的效果通常欠佳。
对于行为克隆训练生成NPC模型,代表性的研究见表5-5。
表5-5 行为克隆模型论文

(2)逆强化学习
逆强化学习也是一种典型的模仿学习方法,其学习过程与强化学习利用奖励函数训练策略相反,不需要对奖励函数进行设计,而是通过对专家数据的学习获取一个奖励函数,并可以进而利用奖励函数对NPC模型进行训练。
IRL的基本准则是:通过迭代奖励函数R来优化策略,并且使得任何不同于专家数据策略πE的动作决策a∈A\aE都尽可能产生更大损失,从而实现对专家数据的最大化模仿。该准则用公式可以表示为
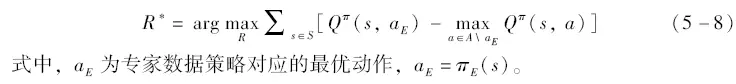
但采用上述方法时,如果需要在学习奖励函数的同时获取NPC模型,还需要使用强化学习对模型进行训练优化,这要求迭代优化奖励函数的内循环中解决一个马尔可夫决策过程(MarkovDecisionProcess,MDP)的问题,会带来极大的时间消耗成本。
对抗逆强化学习(AdversarialInverseReinforcementLearning,AIRL)算法中引入了对抗生成网络(GenerativeAdversarialNetwork,GAN),能够有效提升训练效率。该算法背后的基本概念是同时训练代表驾驶员模型策略的生成器和学习目标奖励函数的判别器,当输入的状态-动作对更有可能来自专家数据演示时,判别器会给予策略模型更高的奖励。AIRL算法能够在判别器和生成器进行对抗的过程中达到博弈均衡,从而同时完成对两个网络的训练并达到相互统一,在时间效率和训练效果上得到显著提升。
在AIRL中,判别器是其中最关键的组成部分,通常可以将判别器表达成

经过AIRL的训练,可以在获得与专家数据相符的奖励函数的同时,获得一个经过充分训练的NPC模型,有效提升训练效率。
与行为克隆相同,由于训练数据中存在专家数据,因此IRL方法训练的模型能够很好地学习到专家数据的行为,生成的模型具备很好的真实性,且由于对抗生成网络的存在,其真实性通常比行为克隆还略高一些。此外,除了专家数据,IRL也会利用仿真过程中生成的数据进行训练,因此数据量高于行为克隆,具备较强的演化性。但IRL由于其训练过程较复杂,所以模型生成效率在几种方法中是最低的;而且训练过程中没有对抗性设定,测试性也相对较低。
对于IRL训练生成NPC模型,代表性的研究见表5-6。
表5-6 逆强化学习模型论文

3. 方法对比
从真实性、测试性、演化性、进化性、生成效率五个维度对常见的NPC模型生成方法进行对比分析,分析结果如图5-19所示。
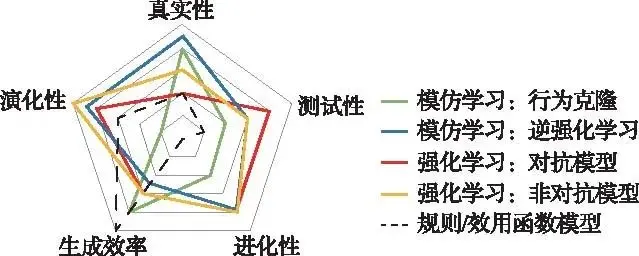
图5 -19 不同模型构建方法特性对比
总体来看,强化学习和逆强化学习在各个维度上的表现都相对较为均衡,是比较理想的NPC模型构建方法。强化学习的优势在于具有最强的演化性;逆强化学习的优势在于可以较好地还原出人类驾驶员的驾驶行为,具有最强的真实性。IDM等基于规则或效用函数的模型生成场景的不确定性较低,模拟车辆特征的真实性有限,现在常作为其他方法的对比基准。
4. 模型生成示例
下面以基于强化学习的模型生成为例,展示NPC模型的具体生成方法和流程。
在NPC模型设计阶段,首先根据不同的交互属性,对模型的特征进行定义。对于交互属性,选择前面所述的中立型、合作型、竞争型模型作为设计目标。对于中立型模型,只关注自车的行驶收益,在进行建模时,将自身的行驶收益目标量化为:①无碰撞行驶;②最大化可行驶区域;③最大化行驶速度。对于合作型和竞争型模型,其考虑的周围车辆包括后观测空间内的所有车辆。对于合作型模型,在中立型对自车行驶收益的考虑之外,还要最大化后观测空间所有车辆的平均速度,以此体现模型的合作特性。对于竞争型模型,还要最小化后观测空间所有车辆的平均速度,以此体现模型的竞争特性。NPC模型的设计方案如图5-20所示。
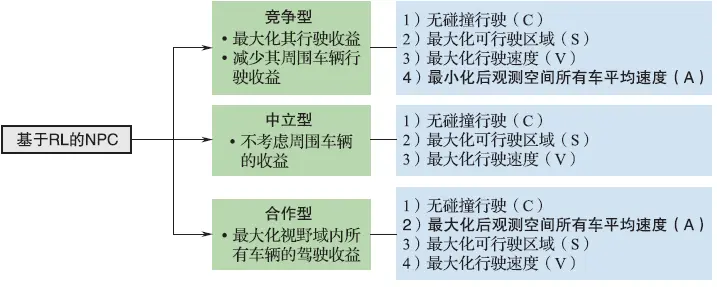
图5 -20 NPC 模型的设计方案
完成模型设计之后,根据设计目标,需要对模型训练使用的奖励函数进行设计。对于中立型、合作型、竞争型NPC模型的设计,奖励函数可以统一设计为
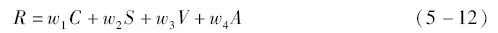
式中,R为奖励的计算结果;C、S、V分别对应自车的三项行驶收益反馈;A对应合作型和竞争型模型对周围车辆收益影响效果的不同奖励反馈。
在完成奖励函数的设计后,采用强化学习的方法完成对NPC模型的训练。基于Actor⁃Critic架构的深度强化学习(DeepReinforcementLearning,DRL)是当前常用的强化学习方法,Actor⁃Critic框架中有Actor网络和Critic网络两个部分,其中Actor网络可以对高维、连续动作空间中的动作进行选取,Critic网络用于对动作的价值进行判断,可以单步更新,更新训练速度更快、学习效率更高。在这种方法中,神经网络作为强大的非线性表达单元被引入强化学习算法中,更适用于驾驶员模型的训练。在本书的示例中,采用了双延迟深度确定性策略梯度(TwinDelayedDeepDeterministicPolicyGradient,TD3)算法进行模型训练,TD3算法是一种常用的强化学习算法,其算法流程图如图5-21所示。
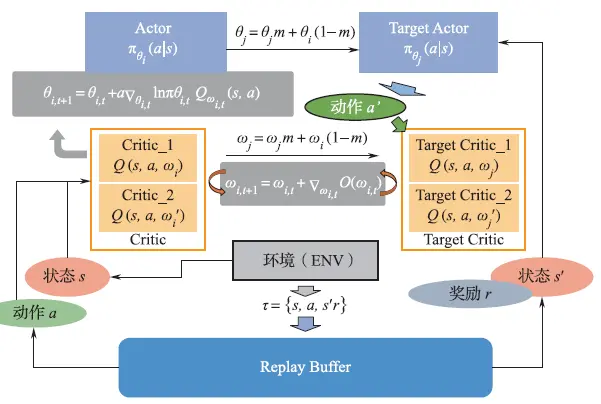
图5-21 基于Actor-Critic架构的TD3算法流程图
本书首先立足于整体现状对智能汽车测试体系架构进行综述, 并针对测试技术的发展趋势和整个核心技术进行详细描述;然后, 针对测试体系中每一测试过程的概念、核心思想、关键技术、测试方法、发展趋势等进行详细描述。
本书可供智能汽车设计人员及测试人员阅读使用, 也可供车辆工程专业及相关专业师生阅读参考。
点击以下链接购买https://mp.weixin.qq.com/s/MlQwkx8HzGRqa4meVhUteQ
作者简介:
陈君毅,2009年毕业于同济大学汽车学院,获工学博士学位,任职于同济大学汽车学院。长期从事自动驾驶汽车测试与评价方向研究工作,先后主持和参与国家级、省部级项目共11项,并与华为、路特斯、上汽大众、蔚来等企业开展了深度校企合作研究。近5年,在国内外学术期刊和国际会议上共发表SCI/EI检索论文近30篇,其中以第一作者或及通讯作者发表的为20余篇;申请发明专利30余项(已授权7项)。担任SAE汽车安全和网络安全技术委员会秘书、功能安全和预期功能安全分委会主席;是自动驾驶测试场景国际标准(ISO3450X)支撑专家组成员,以及CAICV联盟预期功能安全工作组核心成员;担任《汽车工程》和《汽车工程学报》青年编委委员,IEEE Transactions on Intelligent Vehicles、Proceedings of the Institution of Mechanical Engineers, Part D: Journal of Automobile Engineering、《中国公路学报》、《汽车工程》、IEEE Intelligent Transportation Systems Conference、IEEE Intelligent Vehicles Symposium等国内外期刊和国际会议审稿人,曾于多项国际学术会议担任分论坛主席。
版权信息:
智能汽车测试技术 / 陈君毅等著. -- 北京 : 机械工业出版社, 2025. 5. -- (智能汽车关键技术丛书).ISBN 978-7-111-77871-4 Ⅰ. U467 中国国家版本馆CIP数据核字第2025X8D229号
本书由机械工业出版社出版,本文经出版方授权发布。
来源:汽车测试网













