-
模型架构:使用传统的UNet生成occupy grid map,输入是BEV表示下的Radar的点云,输出为occupy grid。
-
模型细节:
-
为什么在极坐标系下检测?
作者提到,CNN对于尺度变化的鲁棒性要强于对方向形状的鲁棒性变化。下图所示,在polar space中路宽相较于cartesian space变化更大,但是cartesian space的两侧点云出现了blur。
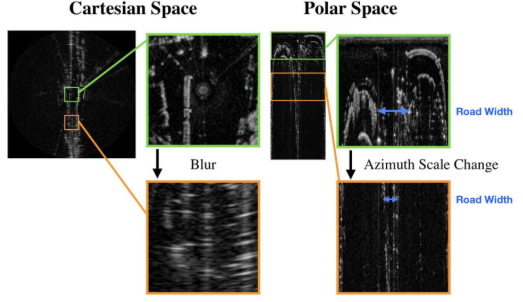
-
毫米波数据预处理
考虑到这样一个问题:毫米波本来检测不到的目标,是否应该强制使其检测?
答案肯定是否,因为毫米波和lidar的性质差异,对于树木等一些反射性相对较差的目标,毫米波是检测不到的,同时radar检测到被遮挡的物体,此时lidar又是检测不到的,两个传感器之间的差异,如果强制检测,会导致相当多的FP预测,因而会降低性能;
因此,通过数据预处理,首先过滤反射强度低于某个阈值的点云,然后将lidar提供的GT数据中radar无法检测到的数据滤除,得到训练数据。
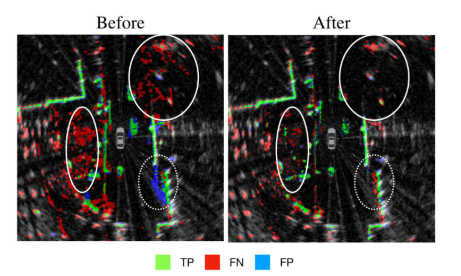
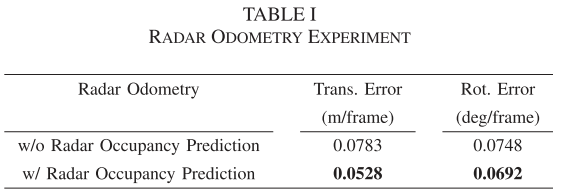
如上图所示,由实验得到,通过预处理,模型的FP大大降低;
-
如何解决传感器检测距离差异问题呢?
POLAR SLIDING WINDOW INFERENCE:将lidar检测区域内的点云作为GT用作traning region,然后逐步滑动窗口,每次窗口所包含的radar点云仅作为inference,生成occupy map。简单来说,就是lidar内的有限数据用于训练,而lidar外的radar用于推理生成occupy map并拼接生成最终的远距离occupy map。
流程如下图所示,这里的内外圆之间的距离是检测的范围,也就是滑动窗口,训练是通过对比不同的滑动窗口的内容与网络预测的同心圆之内的检测结果进行对比训练。
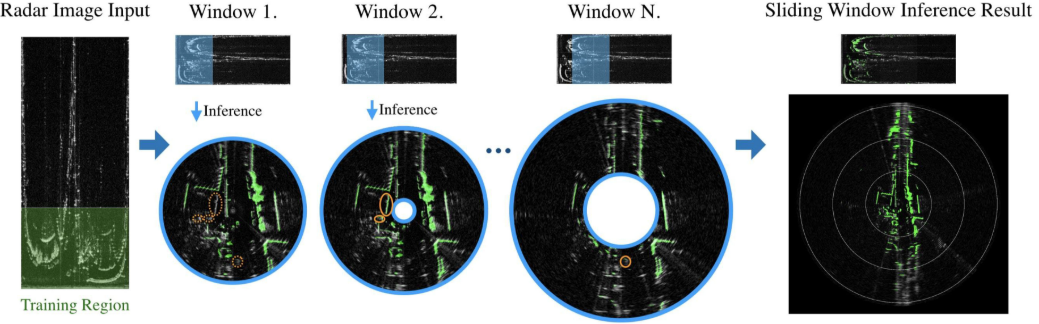
-
如何保持radar的透视性能?
通过上面所述的滑动窗口,可以完美解决lidar监督数据下,lidar-invisible的目标但是radar-invisible的目标点云没有输入而导致的透视性能丧失问题,因为在t窗口不能看到的点云,可以在别的窗口看到。
-
总结:
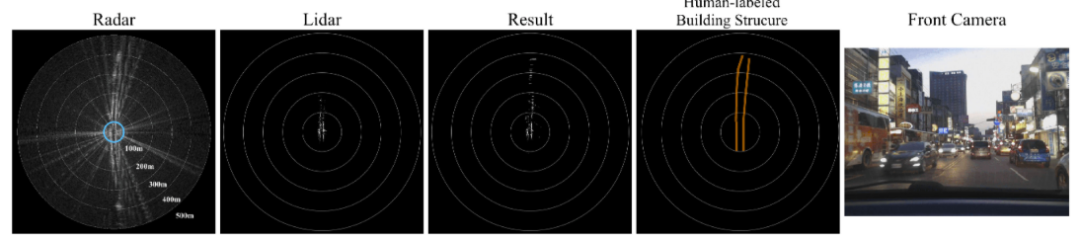
以上是效果图,可以看到,原本的radar输入是非常混乱的,带有非常多的噪声,第二列是训练数据可以看到lidar的点云非常规则能够反映区域内比较完整的几何信息,第三列是输出的结果,通过lidar数据的监督,能够在lidar区域以外,生成噪声较小,能够反映路面分布的点云图。第四列是人工标注的GT,最后生成的result与GT相较radar更为接近。在BEVDepth对网络预测深度监督时,深度本身的模态无关的信息,不加改变地监督深度预测网络是可行的,但是对于radar和lidar两种模态,各自有各自的特性,强制地把一种模态地特征监督另一种模态而不加变化,势必会导致本文中出现的虚警等情况。
来源:自动驾驶之心













